A Multilingual Information Processing Infrastructure for Global Digital Libraries: EPICIST
Noritaka OSAWA
osawa@is.uec.ac.jp
Graduate School of Information Systems
The University of Electro-Communications
1-5-1 Chofugaoka, Chofu-shi, Tokyo 182-8585, Japan
Abstract
This paper proposes and evaluates a character or symbol code infrastructure called EPICIST (Efficient, Programmable and Interchangeable Code Infrastructure for Symbols and Texts) for multilingual and multi-cultural information processing. EPICIST is based on EPICS (Efficient, Programmable and Interchangeable Code System) and includes utilities for multilingual information processing. EPICIST integrates an efficient variable-length coding system, a smart virtual machine and utilities. The variable-length coding system provides a huge code space. This huge space can include not only standardized characters but also user-specific symbols. The smart virtual machine executes inputs as instructions and is dynamically customizable. It allows one to define and modify instructions at runtime. It provides customization facilities. The utilities include facilities for searching, normalization, transliteration and compression of multilingual texts. They are universal and independent of specific languages.
Keywords:
multilingual information processing, variable-length encoding, character code set, smart virtual machine, multilingual utility
1. Introduction
Multilingual information processing has become more important. This is because digital libraries (DLs) and the World Wide Web (WWW) are becoming wide spread, and they are used by people in a lot of nations. Thus DLs and the WWW have to handle multilingual data, and need an integrated and flexible framework for multilingual information processing.
Not only currently used characters in natural languages but also more general symbols should be handled in the framework because DLs need to store, retrieve and process ancient symbols (characters), personal- or company-specific symbols, and different glyphs (Itai-ji) of ideographs as well as standardized characters. In other words, the framework should be able to handle glyphs, marks, signs, logos and so on in addition to characters.
Unicode[12] and ISO 10646[3] are expected to promote the handling of a lot of characters that have been standardized. However, the author thinks that existing character code systems are inflexible and the code spaces are insufficient or inefficient. Existing character code standards intentionally avoid the specific handling of private or personal characters or symbols. They specify only small code regions of private characters. Thus existing standards do not promote global digital libraries which need to use non-standardized symbols. Therefore a new framework is needed in order to store, process and exchange more general or user-specific symbols easily since formal standardization of user-specific symbols is not practical.
In most multilingual information processing systems, implementations are strongly affected by their own concepts of glyphs, characters, scripts and languages. Therefore existing systems usually permit only their own canonical concepts, and force users to obey the concepts. The author does not think that this type of enforcement facilitates present day multi-cultural information processing. Separation of concerns is important in information processing systems. Information processing systems should separate issues of concepts (policies) and those of implementation (mechanism). Multilingual information processing systems should permit various ideas, concepts and policies to coexist, and process various data efficiently using smart mechanisms.
This paper proposes a dynamic symbol (character) code infrastructure for multilingual and multi-cultural information processing. It is called EPICIST (Efficient, Programmable and Interchangeable Code Infrastructure for Symbols and Texts). It is capable of handling general symbols as well as currently used characters, and it is also customizable. In this paper, symbols can include not only characters but also glyphs, marks, signs, logos, tags and even sound elements.
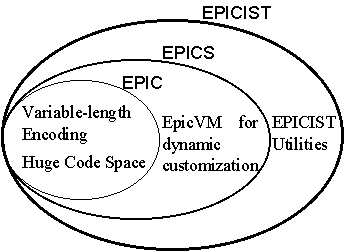
EPICIST is based on EPICS (Efficient, Programmable and Interchangeable Code System) [9] and includes utilities for multilingual information processing. EPICS is a universal symbol code system that enables us to exchange data and to transliterate data efficiently and flexibly. EPICS integrates a variable-length (multi-byte) code system called EPIC (Extensible Process-Internal Code) [7], whose unit is 16 bits, and a smart virtual machine[8] called EpicVM. Features of EPICS are as follows: efficient variable-encoding, huge code space and dynamic customization. Figure 1 shows relationships among EPICIST, EPICS and EPIC. EPICIST does not specify policies but provides an efficient mechanism as an infrastructure for multilingual information processing.
Customization and standardization are not antithetical concepts but are complementary to each other. The process of standardization will not terminate in our evolving world. Thus customization will be needed. An important thing in information systems is adaptability in changing environments.
Features of EPICIST will be explained in the following sections. Due to space limitation, features of EPICS will be mentioned briefly. Please refer to our manuscript* [9] for details of them.
Figure 1: Relationships in EPICIST
2. Efficient Variable-length Encoding
A unit of EPICS is a 16 bit long or wide character. The unit is referred to as EPICU. A symbol in EPICS consists of one or more EPICUs. The most significant bit is BIT 16 in EPICU and the least significant bit is BIT 1. The two most significant bits in a unit indicate if the unit is the head of a symbol or the tail of it. If BIT 16 is 0 in an EPICU, the EPICU is the tail of a symbol. An EPICU whose BIT 15 is 0 is the head of a symbol. If both BIT 16 and 15 of an EPICU are 0, the EPICU is a symbol itself. This coding makes locating boundaries of a symbol easy and efficient.
Some people who have made programs that handle ISO 2022[2] believe that the use of variable-length codes makes programming difficult. However, the main reason for the difficulty of handling ISO 2022 is not variable length but state management of ISO 2022 characters. Moreover, using Java language or a smart pointer in the C++ language, programmers do not need to be aware of the length of a character code. Variable-length encoding is not a problem in programming.
3. A Huge Code Space
Variable-length coding makes a very huge code space available. This huge code space can include not only standardized characters but also more general symbols and user-specific symbols or images.
The symbol code space of EPICS can be divided into subspaces. There are standardized character set subspaces, EpicVM subspaces, user-specific subspaces and temporary use subspaces. Symbol code values composed of one or two EPICUs are mainly used for standardized characters and EpicVM instructions. 3-EPICU symbols are reserved for future standardized characters. Symbol code values composed of 4 or more EPICUs can be utilized for user-specific or temporary symbols.
Following the Unicode standard, the character code value of Unicode is represented by U+nnnn where nnnn is a four digit number in hexadecimal notation. A symbol code value of EPICS is represented by "P+" and 4-digit hexadecimal numbers with dots as separators. For example, an EPICS symbol composed of 1 EPICU is represented by P+nnnn, and a 2-EPICU symbol is represented by P+nnnn.nnnn.
3.1. Standardized Character Set Subspaces
Some parts of EPICS are based on Unicode. Lower code values of Unicode are identical to code values of EPICS except unified CJK (Chinese, Japanese and Korean) miscellaneous characters. For example, codes between U+0000 and U+2FFF correspond to codes between P+0000 and P+2FFF respectively, and the code region between U+3000 and U+3FFF are mapped to the region between P+8000.7000 and P+8000.7FFF.
3.2. EpicVM Instructions
The code region between P+3000 and P+3FFF is used and reserved for EpicVM instructions and numerical representation.
The code region between P+3000 and P+3CFF is available for user-defined EpicVM instructions. Not only a codepoint in that region but also a codepoint in other regions can be used for a user-defined EpicVM instruction, however, unassigned codepoints of 1-EPICU symbol exist only in the above code region. The code region between P+3D00 and P+3DFF is used for exception handlers. The code region between P+3E00 and P+3EFF is used for predefined EpicVM instructions. The code region between P+3F00 and P+3FFF represents the range of integers between -128 and 127.
4. A Smart Virtual Machine
EpicVM is a smart virtual machine and is also a stack-based virtual machine. It is a new type of virtual machine. EpicVM decodes an input symbol as an instruction and executes it. EpicVM allows one to define or modify its instruction definitions using instructions that have been defined during runtime. On the other hand, a usual virtual machine like Smalltalk bytecode machine and Java virtual machine[5] have a fixed instruction set, and they do not allow one to change instructions dynamically.
EpicVM allows a user to define a code sequence at a codepoint. When a symbol is inputted, a specified code sequence is invoked. For example, if a user specifies normalization of external user-specific symbols, the inputted external symbols are converted to normalized symbols.
A code sequence may include instructions. In other words, instructions at a codepoint can call already defined instructions. This makes it possible to invoke instructions as functions or procedures. By utilizing EpicVM, symbol images, font images and so on can be defined and transferred.
Most instructions of EpicVM are similar to instructions of other virtual machines like Smalltalk-80 bytecode machine. However, instructions to define or modify an instruction are specific to a smart virtual machine like EpicVM.
A prototype EpicVM has been implemented using the Java programming language. Java Workshop 1.0 and JDK 1.0.2 were used as a development tool. The total number of lines in source files was about 700 including comments and blank lines. This shows that EpicVM is small and is easy to implement.
5. Utilities and Applications
Multilingual information processing for DLs needs various functions. To support the various functions efficiently, integration is important. EPICIST provides a framework where not only standardized characters but also symbols for research and user-specific symbols can be included. Various types of symbol processing like searching, substitution and sorting can be done using general software tools in the framework.
5.1. Searching
EPICIST provides a string searching utility. The utility reads a specification of search strings and produces a program written in EPICS which invokes a special instruction to notify a user when a search string is found. A user feeds the program into an EpicVM and then a target text. The program can handle both standardized symbols and user-specific symbols. Special tools for user-specific symbols are not needed.
5.2. Normalization and Transliteration
A slight modification of the search utility achieves string substitution. The modified utility reads a specification of substitution and produces a program written in EPICS which substitutes strings according to the specification.
It is difficult to standardize ancient characters which are not used in daily life but are being studied. If researchers have different opinions about identities of symbols, standardization is impossible or at least difficult. EPICIST allows researchers who have different opinions about the identification of symbols to assign symbols to different codepoints and proceed with their studies. Once standardization has been completed, an EpicVM in EPICIST can be customized to map old codepoints to standardized ones.
5.3. Sorting
Sorting is also important in information processing. The desirable order of symbols is dependent on the purpose. The POSIX locale model allows only one sorting order in one language. It is difficult to customize the sorting order in the model. EPICIST makes it easy to customize the sorting order. If one customizes an EpicVM which maps symbols to integers and the mapped integer values are used to sort data, the desirable sorting order can be achieved. Special mapping table structures are not needed. The mapping information is portable because the mapping information can be fully expressed as a sequence of symbols (instructions) in EPICIST.
5.4. Compression
Data compression by defining codes in EPICIST decreases the length of the data and increases the density of data. An information producer can choose an appropriate algorithm for data contents. It is also possible for a producer to gradually send decompression program fragments and compressed data that uses defined codes, and for a consumer to expand compressed data gradually on a stream-type communication. This method reduces the latency of recovering symbols from compressed data on a stream-type communication or slow I/O devices. Other character code sets like Unicode and ISO 2022 do not have functions in order to reduce the length of data.
A prototype one-pass utility program produces compressed data and incremental decompression routines. The length of a text encoded in EPICIST can be shorter than that of the text encoded in UCS-2 or UTF-8.
5.5. Indication of Intentions
EPICIST pays serious attention to both intentions of an information producer (sender) and requirements of an information consumer (receiver). The sender can specify alternatives for symbols in EPICIST. In other words, a sender can send his intentions to a receiver. The receiver may use alternative symbols that are specified by a sender, or may ignore the alternative symbols.
5.6. Internationalization of Markup Tags
Fancy texts consist of not only characters but also language tags and formatting tags. All of them should be internationalized. Standard General Markup Language (SGML) [1] and Hyper Text Markup Language (HTML) [10] are examples of tags or markups in fancy texts. However, tags in HTML are mainly based on English words. The author does not think that internationalization of SGML and HTML is enough.
We can assign a symbol code value in EPICIST to every tag which is composed of characters in markup languages because the code space of EPICIST is huge. If a tag is represented by a single symbol, processing software can be simplified. Internationalization of tags can be accomplished using EpicVM which maps (or transliterates) the symbols to character strings in a user's native language. For example, the tags specified in Text Encoding Initiative guidelines (TEI)[11] can be assigned to symbol code values. This makes internationalization of tags in TEI easy.
6. Related Work
Unicode and ISO 10646 is important as a base for multilingual processing now. However, the encoding of Unicode and ISO 10646 is static and inflexible. The code space of Unicode is too small. On the other hand, 4-byte fixed-length codes like UCS-4 in ISO 10646[3] have a large code space, and are easy to handle within a program. However, when a code is exported outside the program, that encoding is inefficient.
A character set based on ISO 2022 and ISO 2375 is specified by each nation's standardization organization. Therefore, conceptual separation between languages and characters is insufficient. Thus a conceptually identical character can have different codepoints in different code sets. ISO 2022 uses a small code space and switches code sets mapped to the space. This complicates state management of characters.
Internal codes of Mule (MULtilingual Enhancement to GNU Emacs) [6] are mainly based on ISO 2022. Thus separation between languages and characters is insufficient. Mule's encoding does not allow one to apply existing matching algorithms for fixed-width encoding to data simply using a byte as a unit because the existing matching algorithms do not recognize boundaries of a variable-length character in Mule's encoding properly.
The system developed by Kataoka et al. [4] provides a mechanism for code conversion between external codes and internal fixed-width codes (wide characters). Its encoding scheme is the same as usual systems. Furthermore, its implementation does not support separation of concerns. Therefore it is not guaranteed that it can efficiently handle general symbols needed in global digital libraries and various studies.
7. Concluding Remarks
This paper has presented a new multilingual information processing infrastructure called EPICIST. The author thinks that EPICIST promotes efficient internationalization and multilingualism without imposing fixed character sets on people. EPICIST is derived from a unique combination of an efficient variable-length coding system, a smart virtual machine and utility functions.
The variable-length coding of EPICIST provides one with a huge code space and makes it possible to include various characters needed for internationalization efficiently. EpicVM allows one to exchange not only static characters but also dynamic programs. Utility functions allow one to process multilingual data uniformly.
Acknowledgments
The author would like to express his gratitude for the guidance and encouragement received from Prof. T. Yuba.
References
-
[1]
- ISO, Standard Generalized Markup Language, ISO 8879:1986, 1986.
-
[2]
- ISO, Information processing - ISO 7-bit and 8-bit coded character sets - Code extension techniques, ISO 2022:1986, 1986.
-
[3]
- ISO/IEC, Information technology - Universal Multiple-Octet Coded Character Set (UCS) - Part 1: Architecture and Basic Multilingual Plane, ISO/IEC 10646-1:1993(E), 1993.
-
[4]
- Kataoka, Y. et al. , "Internationalized Multilingual System - The Waseda I18N & ML System," Digital Libraries, No.6, 1996 (in Japanese) .
-
[5]
- Lindholm, Tim and Frank Yellin, The JavaTM Virtual Machine Specification, Addison-Wesley, 1996.
-
[6]
- Nishikimi, Kimiko, et al., "Mule: MULtilingual Enhancement to GNU Emacs," Proc. of INET'93, 1993.
-
[7]
- Osawa, Noritaka and Norio Kimura, "A Programming Language 'Kinari'," Technical report of TRON technical meeting, Vol.5, No.2, pp.39-50, 1993 (in Japanese).
-
[8]
- Osawa, Noritaka and Toshitsugu Yuba, "A Dynamically Customizable Virtual Machine used as a Substratum in Heterogeneous Distributed Environments: PivotVM," Proc. of Computer Systems Symp. 1996, pp.81-86, 1996 (in Japanese).
-
[9]
- Osawa, Noritaka and Toshitsugu Yuba, "EPICS: An Efficient, Programmable and Interchangeable Code System for WWW," (Poster) CD-ROM of 6th World Wide Web Conference, 1997.
-
[10]
- Raggett, Dave., HTML 3.2 Reference Specification, W3C, .
-
[11]
- Text Encoding Initiative, .
-
[12]
- The Unicode Consortium, The Unicode Standard, Version 2.0, Addison Wesley Developers Press, 1996.
* http://www.yuba.is.uec.ac.jp/~osawa/research/www6/ (as of September 1997)
{kind=link}