Keyfact-Based Information Retrieval System
Mi Seon Jun,
Se Young Park
System Software Department
Electronics and Telecommunications Research Institute
TaeJon, Korea
{msjun, sypark}@computer.etri.re.kr
Abstract
This paper describes a new automatic indexing method for Korean texts using the keyfact includes simple syntactic relations between adjacent words suitable for agglutinative languages, especially for Korean. We present the construction rules to compose keyfacts as indexing terms. The keyfact is defined a relevant pair controlled by predefined keyfact rules and is expressed in [head word, dependent word]. This method simplifies processing of compound noun, noun phrase, verb phrase and adjective phrase. By applying the keyfact concept, our system has raised the precision ratio of indexing terms.
Keywords
Relevant pair, syntactic relation, compound noun, noun phrase, adjective phrase, keyfact rules.
1 Introduction
Recently some information retrieval(IR) systems provide natural language text or natural language query processing mode for end-users who don't know knowledge and method about system usage than retrieval experts who is proficient in indexing vocabulary. Practically the systems adopt keyword indexing method almost. The keyword is includes compound word as well as single word. The nouns and compound nouns are the most important elements for representing a fact in a natural language sentence. However besides these keywords, verb and adjective have an important role in a sentence[7,8]. Peoples use verb/adjective to represent act/state as well as things within a sentence[3,5]. If there are not any syntactic relations between keywords, wrong combination of keywords cause retrieval of irrelevant documents and omission of relevant documents. In Korean there are too much inflected forms of adjective and verb. People uses single concept, link, role indicators, relators, and composition order as methods to represent syntactic relations between words. Practically some part of the role indicators and relators include semantic relations than syntactic relations and there are semantic components in it. In this paper, we take account of IRS, exclude semantic components and complex syntactic relations. Instead we find head word(noun) and dependent word(noun, adjective, verb) pair by using keyfact construction rules. The rules have maximum 6 window size without considering position of function words at present.
In the following sections, we (1) describe problems of keyword indexing; (2) observe the keyfact concept; (3) show how the keyfact can be extracted; (4) show keyfact generation result; and (5) make suggestions for future research.
2 Problem of keyword indexing
We aim at high precision using keyfact-based index terms. Controlled vocabularies enhance precision ratio because of resolving of homonym and reduce the indexing file size. But it is required that the cost of maintenance of thesaurus and human efforts. And there is inconsistency of indexing. The inconsistency of indexing exists even when a people indexed a same document at the different time as well as when two different peoples indexed a same document. Controlled vocabulary cannot deal with the problems quickly when new vocabulary and concept come into being in a branch of learning. Because new vocabulary does not added to revised edition of thesaurus until it is estimated and applied enough. And it is impossible to enumerate all sub-concepts about a concept.
There are many problems when we use uncontrolled indexing language, that is, natural language. It is caused by synonymy, homonym, semantic ambiguity, contextual ambiguity, and impossible hierarchical retrieval , etc. In case of information retrieval system for Korean, Because Korean has an advancement of postposition, the simple IR system assigns nouns or compound nouns as index terms by using only postposition lexicon without morphological analysis. Recently, it is customary to use compound words as well as single words as indexing terms for the representation of natural language text. The two units have the relative merits. Indexing based on single word unit degrade precision and large indexing file size. It is possible to retrieve user's information need even when user can't remember the whole term about something. In case of compound word unit, in the previous IR systems, possessive postposition 'of(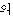 )' was processed by using heuristic rules at the stage of the syntactic analysis after decomposing a noun and postposition at the stage of the morphological analysis. It has some problems as follows. Ideal system must assign compound word "information retrieval(
)' was processed by using heuristic rules at the stage of the syntactic analysis after decomposing a noun and postposition at the stage of the morphological analysis. It has some problems as follows. Ideal system must assign compound word "information retrieval(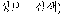 )" as indexing terms by manipulating various expressions such as "about information retrieval(
)" as indexing terms by manipulating various expressions such as "about information retrieval(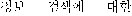 )", "retrieval of information(
)", "retrieval of information(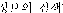 )", "retrieval about information(
)", "retrieval about information(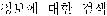 )", "retrieve information(
)", "retrieve information( )", "retrieved information(
)", "retrieved information(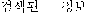 )", etc. Errorous combination of keywords such as "retrieved information" cause retrieve irrelevant documents, because two words 'information' and 'retrieval' can be out of order,. By composing two or more words simply, simple system can't represent the same concept as phrase using above various syntax. It is more difficult to control contextual ambiguity[9]. As you can see the above examples, there are many problems which can not be solved by existing simple phrase unit. To solve the problems, it is necessary to represent syntactic relations effectively.
)", etc. Errorous combination of keywords such as "retrieved information" cause retrieve irrelevant documents, because two words 'information' and 'retrieval' can be out of order,. By composing two or more words simply, simple system can't represent the same concept as phrase using above various syntax. It is more difficult to control contextual ambiguity[9]. As you can see the above examples, there are many problems which can not be solved by existing simple phrase unit. To solve the problems, it is necessary to represent syntactic relations effectively.
To represent syntactic relations between keywords, role indicator and link can be used. For example a document d1 dealing with the subject about 'harmful poisonous to fish' and a document d2 dealing with the subjct about 'poisonous produced by fish'.
In the case of word combination, 'fish' and 'poisonous' are extracted by index terms. Practically though subjects of two documents are different each other, same words are indexed. To settle problems of erroneous retrieval by the wrong combination of each concept, document number and link added to keyword. The examples are belows.
cD1: the great names of the West represented in Korean document -> Korean 150A, document 150A, the West 150B,the great names 150B
D2: the great names of Korean represented in West document -> Korean 150A, document 150A, the West 150B,the great names 150B
At this time role indicator can be used for precise index. The examples are belows.
D3: poisonous produced by fish -> fish(producer), poisonous(producer)
D4: harmful poisonous to fish -> fish(patient), poisonous(agent)
Role indicator defines concept relations. In the case of two concept, several relation symbols are used for representing syntactic relations between two concepts. On the other hand our keyfact-based representation for index terms handle words of more than two words(concept).
3 Keyfact Concept
Keyfact is defined as a relevant pair between head and modifier/predicate and it is represented as [head, modifier/predicate] type. Each keyfact is syntactic unit controlled by keyfact generation rule with maximum 6 window size now. Head word is a content word and can be modified by verb/adjective as well as nouns. The part-of-speech of head word generally can be noun. On the contrary dependent word modifies head word, precede the modified words without exception, and is predicative. : verb/adjective precedes the nouns, noun precedes noun. The part-of-speech of dependent word can be noun, verb, and adjective. When a noun modifies another rear noun, rear noun represents whole concept. Compound noun which is formed front simple noun and rear simple noun represents a specific concept than whole concept. A sentence can be formed one or more object and predicate. In a sentence several methods can be used to represent the same concept. At this time if the concept/fact is the same each other, the keyfact is the same too. Namely one keyfact can not have the same syntax type lexically or syntactically. Keyfact-based index term must be representative and recurrent. For example noun phrase like "method for collecting gas which be fusible in the water and be light than air" satisfy representative condition. But the phrase don't satisfy recurrent condition. So several keyfacts must be extracted from the phrase.
4 Keyfact generation
Meadow defined that if a compound word can not separate two words and occur in a predefined lexicon and the compound word is descriptor too[6]. And he defined term is a single syntactic unit which combined by descriptors. The definition of compound word is used in this paper. For example 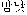 (night and day) has a semantics of always or all the time. Therefore the word hasn't the same relevant nouns and relevant verbs as
(night and day) has a semantics of always or all the time. Therefore the word hasn't the same relevant nouns and relevant verbs as  (night) and
(night) and 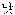 (day) have.
(day) have.
There are three main groups of noun phrase, adjective phrase, and verb phrase. we define keyfact is a adjacent relevant pair. Head-modifier pair is found in a pair, or head-predicate pair can be appear in a keyfact. If head word is nil, the keyfact is worth nothing as a keyfact. On the contrary if dependent word is nill, the keyfact is worth as a keyfact.
In Korean natural language processing, complete morphological analysis and syntactic analysis is very difficult. In the case of automatic indexing, it is not effective. Therefore all inflectional forms of endings are registered in the lexicon and we focused in finding basic forms. So we don't attempt semantic analysis. Basis of morphology separation is not semantics of morpheme itself but stored unit in a lexicon. This method simplify processing of morpheme separation and combination. Especially verb and adjective derived from noun by attaching verbal suffixes like '-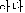 (Hada)', '-
(Hada)', '- (Daida)' etc. In this case sufficient meaning is represented by only noun. Syntactic role of the verb/adjective can be predicative or modifier according to their derivation form. In this case the keyfact generation step is as follows; 1)verbal suffixes are removed, i.e. after stemming 2)noun form appears in dependent word position of keyfact. This information acts essential processing in extracting proper and precise index terms. For extracting keyfact necessary three steps are follows.
(Daida)' etc. In this case sufficient meaning is represented by only noun. Syntactic role of the verb/adjective can be predicative or modifier according to their derivation form. In this case the keyfact generation step is as follows; 1)verbal suffixes are removed, i.e. after stemming 2)noun form appears in dependent word position of keyfact. This information acts essential processing in extracting proper and precise index terms. For extracting keyfact necessary three steps are follows.
Morphlogical analysis for keyword
This step distinguishes primitive basic words-noun, verb, adjective, postposition by using dictionary. There are 25 tags for simple nouns, compound nouns, special symbols, postpositions, conjunctions, verbs and adjectives. The noun represents syntactic relation toward other words by adding postposition. So postposition is used for only keyfact generation based on keyfact rule. Consequentlly the postposition doesn't appear in head word or dependent word position of keyfact.
Syntactic analysis for noun-noun phrase
Noun phrases are easily generated by compounding existing words, with the result that the same meaning is expressed using different words which have common component words[10]. Each component word within a compound is extracted as an independent keyword as well as the formation of a compound word is not ignored.
A retrieval based on simple word can exclude the falsely matched texts from the naive method. There are three kinds of tags-1)some tags must be removed unconditionally, 2)some tags must be removed under prescribed condition, 3)some tags can not be removed in all cases. For example, Korean word '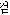
 (computer) can be concatenated with the suffixes '
(computer) can be concatenated with the suffixes '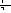 [noun]', '
[noun]', '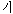 [ga]' when the word is a subject in the sentences and can be concatenated with the suffix '
[ga]' when the word is a subject in the sentences and can be concatenated with the suffix '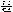 [lul]' when the word is an object. In most cases the suffixes are not useful for representing the contents of document or query texts. Most common and important syntactic rules in Korean are compound words and noun phrase. 3 main groups of compounds: noun, verb and adjective compounds. In this step, compound noun and noun phrase which is composed by two or more nouns are handled. verb phrase is handled next step. Generally the rear noun can be modified by front nouns. Besides compound nouns separated by space character, the front noun and the rear noun of possessive postposition '
[lul]' when the word is an object. In most cases the suffixes are not useful for representing the contents of document or query texts. Most common and important syntactic rules in Korean are compound words and noun phrase. 3 main groups of compounds: noun, verb and adjective compounds. In this step, compound noun and noun phrase which is composed by two or more nouns are handled. verb phrase is handled next step. Generally the rear noun can be modified by front nouns. Besides compound nouns separated by space character, the front noun and the rear noun of possessive postposition '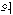 of' form a compound noun or noun phrase.
of' form a compound noun or noun phrase.
* Noun-noun relation
- N1 + N2 -> [N1,NIL], [N2,NIL], [N1 N2, NIL]
- N -> [N,NIL]
In this step, keyfact candidates are extracted based on only their parts of speech. However, judging whether a word is suitable for a keyword requires other syntactic and semantic information than part of speech.
Syntactic analysis for predicate/modifier
This step distinguishes complex word groups-adjective phrase, verb phrase. We defined 22 syntactic patterns for kefact rule. We establish a keyfact generation rule taking into account the proceeding and following words. We'll explain a keyfact generation method using keyfact rules later. If the step II is processed, a sentence is represented by tag sequence such as KEY(keyword), VH(transformed verb/adjective), VB(pure verb/adjective), J(postposition), JY(possessive postposition), etc. Tag sequence is compared with predefined keyfact rules and generates keyfacts suitable to the syntactic property. Our method is simpler than a fully syntactic approach. The fully syntactic analyses have several problems[10]: (1)It's difficult to analyze sentence correctly by the current technology,so the result may include errors or man-machine interaction is required; (2)Because existing parsers are usually very complicated and large program, they are too bulky for adoption into an information retrieval system. As a result, we conclude that our syntactic approach doesn't pay and adopt rather simple approach, i.e. only keeping the ordered simple words. Korean verb and adjective have much more inflected forms compared with English and French. The most noun can be modified by verb/adjective as well as nouns.
As a result of keyfact-based indexing, relevant informations get together under each index term, and inverse index file is made. Following examples show extracted keyfact by keyfact generation rules.
* Adjective-noun
- Key1 J MP Key2 -> [Key1,NIL], [Key2,NIL], [Key1,MP]
- Key1 J MP Key2 JY Key3 -> [Key1,NIL], [Key2,NIL], [Key3,NIL], [Key1,MP], [Key2,Key3], [Key2 Key3,NIL]
- MP Key1 -> [Key1,NIL], [Key1,MP]
* Additional relation
Key1 JK Key2 -> [Key1,NIL], [Key2,NIL], [Key1 Key2,NIL], [Key2 Key1,NIL]
* Predicative relation
- Key J VB -> [Key,NIL], [Key,VB]
- Key J VH -> [Key,NIL], [Key VH,NIL], [VH,NIL]
5 Empirical Results
Precision ratio and recall ratio are the value of measurement used as factors to represent effectiveness of IRS since Cleverdon 1962. Recall is defined as the number of relevant documents retrieved divided by the total number of relevant documents in the collection, and precision is defined as the number of relevant documents retrieved divided by the total number of documents retrieved. Precision ratio and recall ratio are in inverse proportion. Keyword based indexing result have indexing terms such as 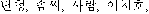 ,
, 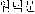 , and
, and 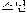 . There are keyfact generation results of a sentence observed through the three steps as follows.
. There are keyfact generation results of a sentence observed through the three steps as follows.
Input (a sentence)

English: There are two priests LeeChiHo and WonDukMoon for a man having excellent painting skill.
Step I (morphological analysis)
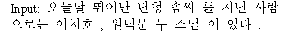
Output: N MP NB NB J MP NB J NQ SF NQ U NB FW SP
Step II (noun phrase generation)
Input: N MP NB NB J MP NB J NQ SF NQ U NB FW SP
Output: KEY MP KEY J MP KEY J KEY KEY
Step III(Keyfact generation)
Input: KEY MP KEY J MP KEY J KEY KEY
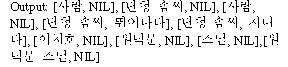
6 Conclusions and Future Work
We have proposed the construction rules to compose keyfact as indexing terms. The keyfact is expressed in [head, modifier or predicate]. A concept which can be represented as various expressions in natural language text can be represented as a keyfact. Since the proposed method does not require a controlled vocabulary or a large thesaurus, it is easy to implement and maintain. Keyfact-based retrieval system attempts to reach beyond the standard keyword approach of simply counting the words from your request that occur in a document. To extract keyfact from text correctly, we used limited boundary of a phrase using the keyfact extraction rule. By applying keyfact, our system has raised the precision ratio of indexing terms.
To represent same concept to one type, controlled vocaburary need not to be. Keyfact-based indexing improve precision because of concrete concept of a document. Because semantic processing is not done. Primitive keyfacts of 'new technology' and 'advanced technology' are [technology, newness] and [technology, advance]. From the point of primitive keyfact, the keyfacts are different each other. Controll of synonym will be handled future semantic clustering. But from the point of extended keyfact, the keyfacts must be same each other. In the future semantic clustering of head word and dependent word is needed.
References
-
1.
- Gerard Salton, Automatic Text Processing. Addison-Wesley Publishing Company, New York, 229-271, 1993.
- 2.
- Yasushi OGAWA, Ayako BESSHO, & Masako HIROSE, "Simple Word Strings as Compound Keywords: An Indexing and Ranking Method for Japanese Texts", In Preceedings of the 16th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 227~236.
- 3.
- Susan Armstrong, "Using Large Corpora", The MIT Press, USA, 1994.
- 4.
- Gerard Salton and Michael J. McGill, "Introduction to Modern Information Retrieval", McGraw-Hill, Inc. USA, 1983.
- 5.
- Frank Smadja, "Retrieving Collocation from Text: Xtract", Association for Computational Linguistics, 143~177, 1993.
- 6.
- YoungMee Chung, "The Theory of Information Retrieval", Gumimuyouk,Seoul, 1993.
- 7.
- Yae, Y.H., Automatic Keyword Extraction System for Korean Documents Information Retrieval, Information Managements Research, 23(1), pp39~62, (in Korean)
- 8.
- Han,S.H., A Design and Implementation of Automatic Indexing System by Using Syntactic Analysis for Korean Text, MS Thesis, Department of Computer Science, Korea Advanced Institute of Science and Technology. (in Korean)
- 9.
- Joon Ho Lee & Jeong Soo Ahn, Using n-Grams for Korean Text Retrieval, In Preceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 216~224.
- 10.
- Yasushi OGAWA, Ayako BESSHO, & Masako HIROSE, "Simple Word Strings as Compound Keywords: An Indexing and Ranking Method for Japanese Texts", In Preceedings of the 16th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 227~236.