日本の World Wide Web 情報空間: 1996年1月のリンクデータ解析
中川 格, 石塚 英弘, 山本 毅雄
図書館情報大学
〒 305 茨城県 つくば市 春日 1-2
Tel: 0298-59-1111(代表), Fax: 0298-59-1093
E-mail:{itaru,ishizuka,yamamoto}@ulis.ac.jp
<URL: http://voyager.ulis.ac.jp/>
概要
ソフトウェアロボットが収集した1996年1月のリンク情報をもとに、
国内のWeb の情報空間の統計的調査を行なった。
早稲田大学村岡研究室の田村健人から提供を受けたデータ(約683万リンク)を使用し、
情報提供を行なっている組織数(3,560)やサーバ数(12,204)に関する基本的な統計量を算出した。
全データのうち、活発にWeb に取り組んでいる1,235組織(active sites)間の約585万リンクから、
1)これらの組織内および組織間のリンク数、2)参照率・被参照率を求めた。
active sites を属性により6グループに分類し、
これらのグループの活動の性格を
1)リンク数の総数・平均値・中央値、 2) 平均参照率・相互参照率
などから解析した。
さらに 総合 Best 50 サイトを選出し、それらの関係を明らかにした。
キーワード
World Wide Web, 情報空間, 統計調査, Active Sites, 日本
Japanese Web Information Network: January 1996
Itaru NAKAGAWA, Hidehiro ISHIZUKA, Takeo YAMAMOTO
University of Library and Information Science
1-2 Kasuga, Tsukuba, Ibaraki 305, Japan
Tel: +81-298-59-1111, Fax: +81-298-59-1093
E-mail:{itaru,ishizuka,yamamoto}@ulis.ac.jp
Abstract
Configuration and activity of Japanese World Wide Web (Web) information
network were statistically studied using 6.83 million link data collected by a software
robot (by Kento Tamura of Waseda University) in January 1996.
Among 3,560 sites running 12,204 servers, 1,235 were chosen as active sites:
links among them were 5.85 million, or 85.6 % of the total.
For each active site,
1) the number of internal, external outgoing, and external incoming links, and 2) referring, and being refereed percentages were calculated.
For six groups of active sites, 1) the total, the average,
and the median of the number of links between groups, and 2) the average referring percentage, and bi-reference percentage were obtained.
The above data were used 1) to analyze the activities of those groups,
2) to choose 50 most active sites, and 3) to elucidate their interdependence.
Keywords
World Wide Web, Information Network, Statistical Analysis, Active Sites, Japan
1. はじめに
本研究では、World Wide Web(Web) 上で情報提供を行っている組織間の参照関係を統計的に調査し、
Web の情報空間の基本的な統計量を算出するとともに、その情報空間がどのように構成されているかを解析した。
解析データはソフトウェアロボットが収集したリンク情報を用いた。
近年Web は目覚ましく発展し、多くの情報がWeb 上で提供されている。
また、情報量の増加にともない、リンクにより形成される情報空間も複雑さを増している。
このため、手探りでリンクをたどって求める情報を見つけ出すことが難しくなった。
この問題を解決すべく、ソフトウェアロボットを利用した情報資源の探索(information
discovery)の研究が盛んに行われている。探索時に見つけられた情報
は、所在情報データベースとして広く利用されているが、それらに関する詳しい統計量は報告されていない。
本研究の調査では、情報の内容には立ち入らずに、
リンク情報のみを使用して国内の組織(``.jp''ドメインの組織)の参照関係を分析し、
個々のページの更新に対してもある程度頑強なWeb の情報空間の全体的な特徴を
抽出する。
このような情報空間の統計的調査は、現在のWeb の状況を知るだけではなく、これまでの
発展の軌跡を記録するとともに今後を予測する上でも重要であり、
Web 上での情報検索を支援するための基礎データを与えるものでもある。
2. 解析に用いたデータ
本研究で用いたデータは、早稲田大学の田村健人が作成したソフトウェアロボット「千里眼」
が収集した生データをもらい受けたものである。
田村は 1994年12月から千里眼を用いて国内のページ情報を収集し、所在情報データベースを作成している。
本研究では、千里眼が 1996年1月に収集したデータを解析した。
オリジナルデータ中には、http オブジェクト、ftp オブジェクト、 gopher オブジェクト、nntp オブジェクト
へのリンクなど、様々なリソースへのリンク情報がある。
ここで、http オブジェクトとは httpd (HyperText Transfer Protocol Daemon )が扱えるオブジェクトの総体である。
その他のオブジェクトについても同様である。
また、httpオブジェクト間リンクの中には特殊なリンクとして、
Delegateなどの中継サーバを介したリンク情報が含まれている。
3. 分析結果
3.1 データのサンプリングと基本統計量
本研究では国内にある httpd オブジェクトとその間のリンクによって構成される情報空間を
調査するために、以下に示すサンプリングを行なった。
- 中継サーバを経由したリンクは、中継サーバを除き、リンク元からリンク先に直接リンクが張られている形に変更する。
- httpd オブジェクト間リンク以外の場合はそのリンクを削除する。
- 国外(JPドメイン以外)のhttpdオブジェクトがリンク先あるいはリンク元になっているものを削除する。
- httpdオブジェクトを提供している組織が実在しない場合はそのリンクを削除する。
このサンプリングにより、オリジナルデータに含まれる6,829,256リンクのうち、
5,950,558リンクが国内httpオブジェクト間リンクとして残った。これはオリジナルデータの87%にあたる。
本研究では、Web 上で情報提供を行なっている組織を、
JPNIC の定めた「JPドメイン名の割り当てについて」[3]
と「JPドメイン名(地域型) 割り当てについて」[4]
に基づいて、第2レベルドメイン名をもとに6つのグループに分類した。すなわち、ac.jp, ad.jp, co.jp,
go.jp, or.jpと、その他の ``others''である(表12)。
国内httpdオブジェクト間リンクから、登録ドメイン名(各組織のインターネット上での名前)と
サーバ名を抽出し、グループごとにそれらの数を集計した。さらに、それらがインターネットに接続している
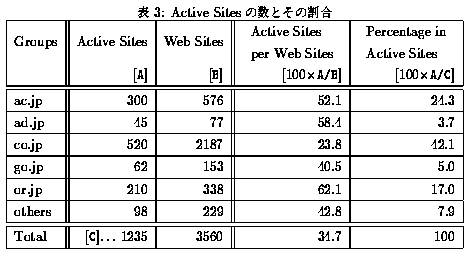
サイト数に対し、どのぐらいの割合かを調べた。その結果を表1に示す。
この表から以下のことがわかる。
なおサイトとは、インターネット上で使われているJPドメインの登録ドメ
イン名を所有している者(組織)とし、実際には「日本ドメイン名一覧表」[5]
のエントリに対応するものとした。
- 全サーバ数の59%を教育および学術機関(ac.jp;以下「大学」と略す)のサーバが占めており、2位の企業(co.jp)とあわせると全体の約84%をこの2つのグループが占める。
- 全サイトの61%を企業が占めており、大学は16%で2位だった。
- 大学は一つのサイトで平均10以上のサーバを運営しているが、多くの企業は1サイトあたり1つのサーバを立ち上げている。
このことから、企業では全社的なコントロールがおこなわれていると予測できる。
- インターネットに接続している全サイト(6,059)のうち、58.8%(3,560) がWeb 上で情報提供を行なっている。
- インターネットに接続している全サイトに対するWeb 上で情報提供を行なっているサイトの割合は、大学、政府関連機関、ネットワーク管理組織が非常に高く、いずれも80% 以上である。
著者らはこれまでの研究[2]において、Web サーバは3種類のリンクの数により特徴づけられ
ることを示した。それらはInternal Links、External Outgoing Links、External
Incoming Links である。サイトを単位とした場合にも同様のことが言える。
その意味は表2のようになる。
上記3560サイト中には、Int. Linksの数が少なく、他のサイトからの参照
(Ext. Inc. Links) 数も非常に少ないサイトも数多く含まれている。本研究で
は、Int. Links が10未満のものと Ext. Inc. Links が10未満の微小サイトを
解析対象外とし、これらのサイトが提供する httpオブジェクトがリンク元あ
るいはリンク先になっているリンクを国内httpオブジェクト間リンクから除い
たものを解析対象リンク(サンプルセット)とした。この結果、1235サイト
(active site)が解析の対象となり、サンプルセットに含まれるリンク数は5,845,417になった。
表3
に、微小サイトを含むサイト数とactive site 数のグループごとの内訳と、全
active site に対する各グループの active site の割合を示す。この表より以下のことがわかる。
- 全体の約1/3 がactive site である。
- 企業サイトは全体の75%が微小サイトであるが、全active site の約40%以上を企業が占めている。
- 団体(or.jp)とネットワーク管理組織(ad.jp)は絶対数は少ないものの、60%近くがactive site である。
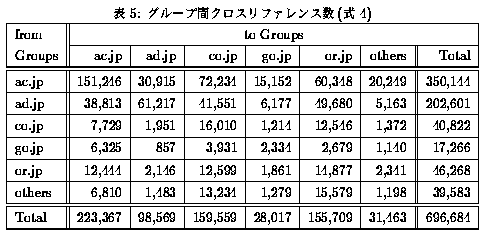
各グループごとに3種類のリンクの総数を表4に示す。この表から以下のことが読み取れる。
- すべての種類において大学が最も大きいシェアを占めている。
- ネットワーク管理組織はInt. Links の数と Ext. Out. Links の数がほぼ同数である。
- 企業は Int. Links の数にくらべ、Ext. Out. Links の数が非常に少ない。
3.2 リンク数行列と参照行列を用いた分析
Web 情報空間のより詳しい解析を行うためにリンク数行列と参照行列を以下のように定義した。
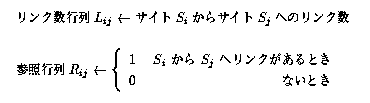
リンク数行列の意義は自明であるが、参照行列を用いることの意義についてはこの節の後半で議論する。
先に述べた3種類のリンクの数は リンク数行列(Lij)を用いると
式1、式2、式3のようになる。

各サイトを、これらの3つの量をもとにプロットしたものを図1に示す。
この図からは、Int. Links と Ext. Out. Links が多い(右上)と Ext. Inc. Links も多く(直径大)なる傾向にあるが、
Int. Links とExt. Out. Links がそれほど多くなくてもExt. Inc. Links が多いものもあることがわかる。
あるグループに属するサイトが同じグループ内のサイトに張るリンクの量と、
他グループのサイトに張るリンクの量を比較し、グループ間の参照関係にどのような
差があるかを調べた。
グループ間の参照量をグループ kからグループ lへのクロスリファ
レンス数(Nkl)とし、式4と定義した。
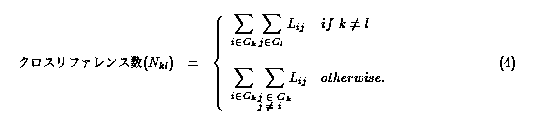
ここで k,l ∈ { ac.jp, ad.jp, co.jp, go.jp, or.jp, others}であり、
Gkはグループkに属するサイトの集合である。
各グループ間のNklの値を表5に示す。この結果から、
ネットワーク管理組織グループ(ad.jp)以外のグループは大学からの参照数が
他のグループからの参照数よりかなり多いことがわかる。
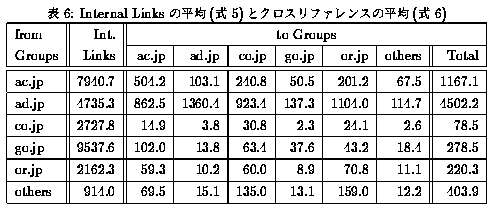
グループごとのInt. Links の平均と、クロスリファレンスの平均は式5および式6となる。
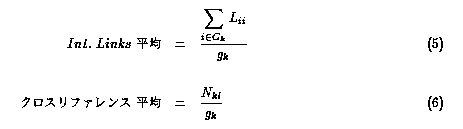
ここで k∈ { ac.jp, ad.jp, co.jp, go.jp, or.jp, others}であり、
Gkはグループkに属するサイトの集合である。
また、gkはGkに属するサイト数である。
この計算結果を表6に示す。
表6からは以下のことがわかる。
- すべてのグループにおいて、Int. Links が各グループへの Ext. Out. Links よりはるかに多い。
- ネットワーク管理組織のExt. Out. Links の合計と Int. Links の合計はほぼ等しい。
- 政府関連機関と ``others'' を除いて、それぞれのグループ内でのクロスレファレンスが多い。
- 企業は他グループへほとんどリンクを張らない傾向にある。
表6のような平均値は例外的に巨大なサイトに影響を大きく受け、
代表的なサイトの特徴が現れていない可能性がある。
そこで、3種類のリンクの各グループごとの中央値を調べた(表7)。
表7と表6を比較するとから以下のことがわかる。
- 企業グループの代表的なサイトは Int. Links が400、Ext. Inc. Links が100に対し、Ext. Out. Links が4と非常に少ない。
- 大学の代表的なサイトは Int. Links が1200で最も多く、他サイトの情報への参照数も、他サイトからの参照も多い。
- 各グループの Int. Links の平均値(表6)と中央値を比較すると、
内部に大量のリソースを持ついくつかのサイトの Int. Links の量が平均値に大きく影響している。
特に政府関連機関のグループにおいてその影響が顕著である。
これらのことからわかるように、小中規模のサイトが大半を占めているにも関わらず、
リンク数による解析は、少数の巨大サイトに大きく影響されている傾向にある。
そこで、参照行列を用いて割合による解析を行なった。以下に解析結果を示す。
まず、各サイトがどのぐらい多くのサイトを参照しているか(参照率;式7)、
あるいは参照されているか(被参照率;式8)を調べた。
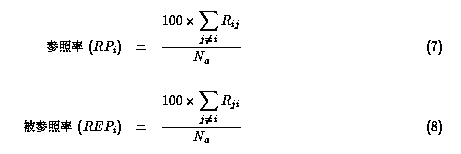
ここでNaは active site 数(1235)である。
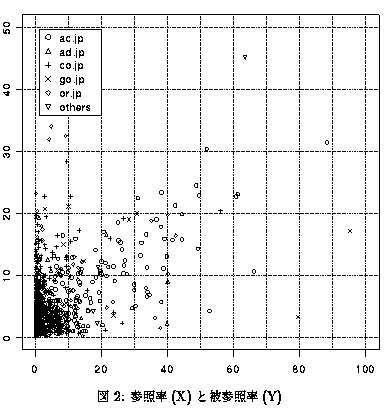
図2に各サイトの参照率、被参照率による散布図を
示す。この図でX軸が参照率、Y軸が被参照率である。この図
において大半のサイトが {0≦X≦10, 0≦Y≦10}
の範囲にあり、参照率・被参照率がともに高いものは重要なハブ・サイト(Hub Site)としての役割を持つと言える。
次に、同じグループ内への参照率と他グループへの参照率を比較し、
グループ間の参照率にどのような差があるかを調べた。
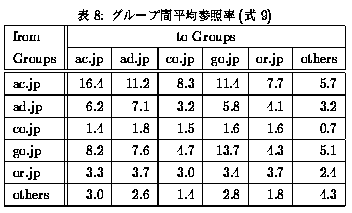
グループk から lへの平均参照率(Pkl) は、式9となる。
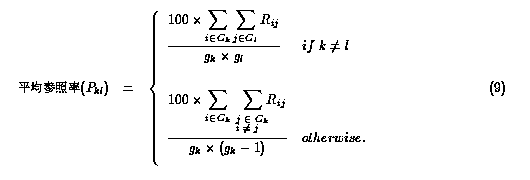
ここで k,l ∈ { ac.jp, ad.jp, co.jp, go.jp, or.jp, others}であり、
Gkはグループkに属するサイトの集合である。
また、gk は Gkに属するサイト数である。
平均参照率(Pklの値は表8のようになった。この表からは以下のことが読みとれる。
- ac.jp--ac.jp 間と go.jp--go.jp間の平均参照率が他に比べ大きい。
- 異なる2つのグループ間の平均参照率は、1% -- 3% 台のものが多い。
活性な参照関係(Rij=1)のうち、お互いに参照しあっているもの(Rij=Rji=1)
がどれぐらいの割合かを調べ、国内全体の参照関係の歪みがどのぐらいあるのかを調べた。
この歪みを調べるために、まず参照行列を3つの行列に分解した。
参照行列 R は、異なる2つのサイト間の相互参照を示す行列と、
片方からのみの参照を示す行列と、内部参照を示す対角行列に分解可能である。
つまり、参照行列 R は双方向参照行列 Rb、単方向参照行列 Rs、
対角行列 D(式10) を用いて
式11のように分解できる。
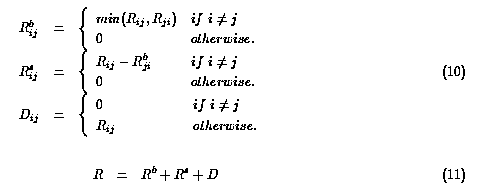
この分解(式11)により、各サイトの参照関係が非対称であることが明らかになった。
これらのサイト間の参照関係の非対称性の度合を調べた。
ある一つのサイト Siteiと、Siteiと
参照関係あるいは被参照関係を持つ(複数の)サイトとの間の相互参照率を
双方向参照行列 Rb、単方向参照行列
Rsを用いて
式12と定義した。
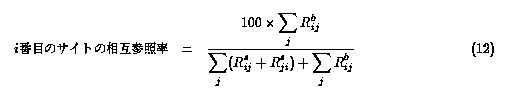
さらに全体の相互参照率は式13となる。
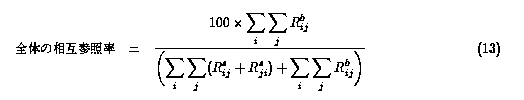
この値は 13.9 となった。
この結果、あるサイトiから別のサイトjへの参照があっても
多くの場合 jからiへの参照は無いということがわかる。
全体の相互参照率が低かったため、個々のグループ間の対称性を調査した。
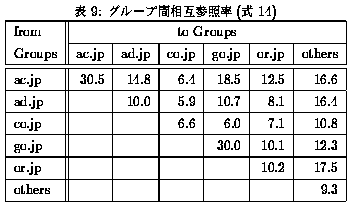
2つのグループkとlの間の相互参照率(Ckl)を、
式13を拡張して式14と定義した。
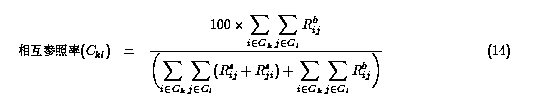
ここで k,l∈ { ac.jp, ad.jp, co.jp, go.jp, or.jp, others}であり、
Gkはグループkに属するサイトの集合である。
Cklの計算結果を表9に示す。この結果から、以下のことがわかる。
- ac.jp 同士、go.jp 同士の相互参照率がもっとも高く30% ちかい。
- その他のグループは、``others'' との間で相互参照率が高い。
- Web 上の参照関係の大半が片方向の参照であり、双方がお互いに参照しあっているものは少ない。
3.3 データ特性
ここでは、リンク数行列(L) と参照行列 (R)の2つの行列からわかる、
Web の 全体的なアクティビティについて議論する。
2つの行列の特徴から、Web の全体的な特徴として以下のことがわかった。
- R≠RT である。
-
⇒ Web のアクティビティを表す行列は非対称行列である。
全体の相互参照率が13.9%であることから、
片方向の参照の方がかなり多いことがわかる。
- L の対角要素の合計は、全体のリンク数の88% を占める。
-
⇒ Web 上のリンクのほとんどは、同一サイト内に向いており、
他のサイトが提供する情報への参照はあまりない。
- R の全要素の 95.6% が 0である。
-
⇒ 全体的な傾向として、あるサイトは少数の特定のサイトにリンクを張っている。
3.4 Best 50 サイトの分析
総合的に最も活発にWeb に取り組んでいるサイトのアクティビティと、
その間の参照関係がどのようになっているかを調べた。
まず、総合 Best 50 サイトを選ぶために、5つの要素から各サイトのスコアを求めた。
その計算式は式15とした。
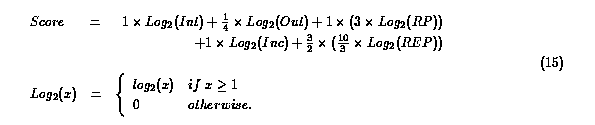
式15の作成にあたって、まずそれぞれの値を等級に分けるために log2 スケールを使用した。
それぞれの重みはInt. Links(Int)を基準とし、以下のような判断により決定した。
- Out (Ext. Out. Links.):
-
Ext. Out. Links は他の人の財産を自分の財産とすべく採り入れたもので、
謂わば他人の褌での勝負である。このため、Int. Links より重みを減らし、 1/4 にした。
- RP(参照率):
-
Yellow Page を提供しているようなサイトは、情報検索の際に有用であり Int. Links と同じ値にした。
Log2(RP) を 3倍しているのはLog2(Int)の値と最大値を揃えるためである。
- Inc (Ext. Inc. Links):
-
他のサイトから参照されているということは、何らかの意味で重要であるこ
とを示しているため、Int. Links と同じ値にした。
- REP(被参照率):
- 多くのサイトから参照されているということは、非常に重要であることを示している。
このため、Int. Links より重い 3/2 にした。
Log2(REP) を 10/3 倍しているのはLog2(Int)の値と最大値を揃えるためである。
このスコアの 上位 50 サイトを Best 50 サイトとし、その結果を表10に示す。
この Best 50 サイトのアクティビティを表11に示す。
表10と表11の2つから以下のことがわかる。
- Best 50 サイトには、大学・プロバイダ・情報関係を扱う企業・政府の研究所が多く含まれる。
- Best 50 サイトのうちの半数以上(32)を大学が占めている。
- Best 50 サイト間リンク(Int. Links も含む)が全 active site 間のリンクの半分近くを占める。
- Best 50 サイトはお互いにほとんどのサイトを参照している。
Best 50サイト間のリンク数のシェア率は Int. Links を差し引いて計算しても
全active site 間の Ext. Out. Links の 28.7 % を占めていた。
Best 50サイト間のアクティビティをわかりやすく表現するために
それらの間の参照関係図を作成した(図3)。
表11からわかるように、すべての参照関係を図に描き込むと、
複雑で見にくい図になる。そこで閾値を設け、それ以上の参照数のものを描き込むという形式をとった。
まず、Best 50サイト間で、サイトSi から サイトSjへのリンク数が
500以上のものを抽出した。
この結果、31サイト間の 60個の参照関係が該当した。これらの関係は、地図中に太い方向付エッジで記した。
次に、地図中に 50 サイトすべてを含ませるために、
図に現れなかった 19サイトに関してその最大の参照先を調べ図に描き加えた。
なお、図中の各サイトを表す円の大きさはスコアをもとに 5点刻に5段階に分けている。
この図からは、以下のことがわかる。
- Web の参照関係は、学術的な部分(大学や研究所を中心としたもの)と
非学術的な部分(企業やプロバイダを中心としたアクティビティ)とに大きくわ
かれるが、境界ははっきりしていない。
- 学術的な部分では、東大が巨大なハブサイトとしての役割を担っている。
- 非学術的な部分では、リムネットをはじめとするプロバイダが中規模のハブの役割を担っている。
図3は、Web のアクティビティを的確に表しているが、複雑で多少見ずらい。
そこで、サイト Siが最も多く参照している外部サイトSjへの方向付
エッジのみを記したものを図4に示す。
4. 考察
本研究では、日本国内のWeb の情報空間の様々な統計量を算出するとともに、
その全体的な特徴の解析を行なった。
これはWoodruffら[7]が必要であると指摘したStructual Network
Analysis のWeb への応用を試みた研究ともみなせる。
まず国内のWeb 上で情報提供を行なっているサイト数やサーバ数などの基本的な統計量を算出した。
これらのサイトのうち、活発に情報提供を行なっている1235 のactive site につい
て、 1)active site 間のリンク数、2)参照率、被参照率を調査した。さらに
active site を6つのグループにわけ、グループ間のアクティビティについて、
1)グループごとのリンク数の平均値と中央値、2)グループ間平均参照率、3)グルー
プ間相互参照率等についての解析を行なった。
さらに、これらの量をもとに 総合Best 50サイトを選び、それらの間のアクティビティを調査した。
これらの解析を通してわかったことには、例えば、1) 各サイト内部への参照
を意味するInt. Links の合計が国内全体のリンク総数の大半を占めていること、
2) Web 上の参照関係は対称ではなくかなり偏りがあること、
3) Web の情報空間には大学や政府の研究所を中心とする学術的な部分と企業や各種団体を中心とする非学術的な部分とがあるが、
境界ははっきりしていなこと、などがある。
これらの解析を通して得られた知識は、データ収集後ほぼ1年経った現在
でも情報検索の際に十分に役立っている。これはWeb の急激な発展を考えると驚異的なことで
ある。
このことは本研究が目標とした、多少の変化に対してもある程度頑強
なWeb の情報空間の全体的な特徴を発見することができたことを意味している。
本研究で行ったようなWeb の情報空間の調査を世界の各地域を対象として行ない、さらに
各地域間の連関を解析することにより、真にWeb の World-Wide な
特徴を浮き彫りにすることができるだろう。
解析を通して得られた知識の中には、1)参照率95%の日本科学技術情報センタ
(JICST)はインターネット上の簡易団体名鑑として有用であること(注1)、2) 多く
の Ext. Out. Links を持つORIONSは、情報検索の際に有用であること(注2)、
3)歴史的に重要な立場にあるNTTは多くのサイトから参照されており、依然として重要な立
場にあること、4)
「賃貸コンテンツサービス」(注3)を提供している
プロバイダはWeb の世界で中規模なハブサイトとして重要な位置を占めていること、
などがある。
一方で、本研究は全体的な特徴を調査することに重点を置いたため、個々のサイ
トに関しては詳しく解析していない。また提供されている個々の情報内容に
関しても解析していない。
実際の個々の情報要求に直接的に対応するには、提供されている情報の内容分析をする必要もある。
本研究で重要であると判明した個々のサイトに対して、例えば、
1)どのような情報を提供しているのか(YellowPage か1次情報か)、
2)主に提供している情報の主題あるいは分野、
3)他のサイトから多く参照されている情報(セールスポイント)は何か、
などの内容分析を行なうと、統計的な判断に基づいた重要な情報(ページ)のみを
見つけることができる。これらのページを体系的にまとめることにより、
多くの利用者が欲すると思われる重要なもののみを集めた、YellowPage を作成することも可能である。
本研究はこのようにWeb の全体的な特徴を解析することにより、
Web の情報検索支援のための基礎データを与えることもでき、
統計データに基づいた情報検索支援ができる可能性をも秘めている。
- 注1):
-
1996 年 10 月1日にJICST と新技術事業団(JRDC)とが統合され、
科学技術振興事業団(JST)となった。現在はこの団体名鑑のページ群は大幅に規
模が縮小されており、残念である。現在のURLは
<URL: http://www3.jst-c.go.jp/Inst_dir/>
- 注2):
-
URL Square (ORIONS), Available from <URL:
http://www.orions.ad.jp/urls/index-jp.html>.
- 注3):
-
プロバイダの多くは、ユーザが自分の情報をWeb 上で情報公開を行なえるような
サービスを展開している。ここではこのサービスを「賃貸コンテンツ提供サービス」と呼んだ。
このサービスを利用して(独自にインターネットに接続せずに)Web 上で情報を公開している組織も多数ある。
今後このサービスを利用して情報提供を行なう組織がさらに増加すると、解析の
際にこれらのプロバイダの特別扱いが必要となるだろう。
参考文献
[1] 中川格. World Wide Web 情報空間の特徴の分析と把握. 修士論文, 図書館情報大学, 1997.
Available from
<URL: http://voyager.ulis.ac.jp/papers/thesis/>.
[2] Nakagawa, Itaru et al.
An analysis of Internet resources: Toward drawing a WWW server relationship map.
Proceedings of Fifth Conference of International Federation of
Classification Societies 96, Kobe, 1996-03, Internatinal Federation
of Classification Societies. Vol.1, p77--80(1996).
Available from
<URL: http://voyager.ulis.ac.jp/papers/abs-IFCS96.ps>.
[3] 日本ネットワークインフォメーションセンター.
JPドメイン名の割り当てについて. 1996-11-06.
Available from
<URL:
ftp://ftp.nic.ad.jp/pub/jpnic/domain-name-all.txt.961106>.
[4] 日本ネットワークインフォメーションセンター.
JPドメイン名(地域型)割り当てについて. 1996-08-05.
Available from
<URL:
ftp://ftp.nic.ad.jp/pub/jpnic/domain-geographic.txt>.
[5] 日本ネットワークインフォメーションセンター.
日本ドメイン名一覧表. 1996-06-08.
<URL:
ftp://ftp.nic.ad.jp/pub/jpnic/domain-list.txt>.
[6] 田村健人. Senrigan search. Available from
<URL:
http://www.info.waseda.ac.jp/search.html>.
[7] Woodruff, Allison et al. An investigation of documents from the World Wide Web.
Proceedings of Fifth International World Wide Web Conference, Paris, 1996-05.
Available from
<URL:
http://www5conf.inria.fr/fich_html/papers/P7/Overview.html>.
compiled by itaru@ulis.ac.jp
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}