美濃導彦
京都大学工学部
〒606-01 京都市左京区吉田本町
Tel: 075-753-5995, E-Mail: minoh@kuis.kyoto-u.ac.jp
池田克夫
京都大学工学部
〒606-01 京都市左京区吉田本町
Tel: 075-753-5371, E-Mail: ikeda@kuis.kyoto-u.ac.jp
MINOH Michihiko
Faculty of Engineering, Kyoto University
Yoshida-honmachi, Sakyo-ku, Kyoto, 606-01, JAPAN
Phone: +81 75-753-5995, E-Mail: minoh@kuis.kyoto-u.ac.jp
IKEDA Katsuo
Faculty of Engineering, Kyoto University
Yoshida-honmachi, Sakyo-ku, Kyoto, 606-01, JAPAN
Tel: +81 75-753-5371, E-Mail: ikeda@kuis.kyoto-u.ac.jp
ディジタル図書館を実現するための重要な課題の一つに、過去から現在にいた る間に出版された膨大な数の図書・雑誌をいかにして効率よくディジタル化す るか、が挙げられる。文書のディジタル化には、ページイメージによるものと 全文テキストによるものとがある[2]。ページイメージは、スキャナによって 文書をビットマップイメージとして取り込んだものであり、作成コストが安く、 閲覧に向くという特徴を持つ。一方、全文テキストは、OCR を利用するなどし て文書をテキストとして表現したものであり、データサイズが小さく、検索に 向いている。しかし、現状の OCR の読み取り精度は十分なものではなく、そ の誤りを人手で修正して完全な全文テキストを得るにはコストがかかり過ぎる。 そのため、全文テキストのみを提供するといった形態は一般的ではない。
それに対して、TULIP[3]で実現されているように、閲覧にはページイメージを 用いながら、OCR で読み取ったままの(修正を加えない)全文テキストを検索用 として利用する形態が考えられる。この方式によれば、ページイメージ方式の 利点(低コスト、容易な閲覧)はそのままに、わずかなデータ量の増加(1/20程 度)だけで、一次データによる全文検索が可能になる。この方式の問題点は、 OCR の認識率が高くなければ検索結果が役に立たないことである。20年来の文 字認識研究の結果、市販の低価格日本語OCRソフトでさえ、高品質の印刷文書 に対しては 92%-98% 程度の認識率を達成しており[4]、これは十分実用に耐え 得る値であると思われる。しかし、実際には、印刷品質が低い文書、フォント が特殊な文書、プロポーショナルフォントが混在する文書などでは認識率の低 下は避けられず、特に古書などでは、現状の OCR では実用に耐えない。
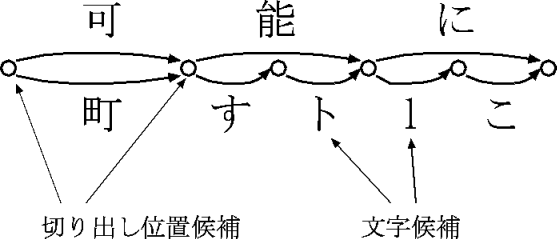
そこで、本稿では、文字認識率が低くても(人手によって修正することなく)全 文検索が可能な手法を提案する。通常の OCR では、ページイメージ(文書画像) をテキストに変換するが、本稿で提案する手法では、「文字ラティス」と呼ば れる形式[5]に変換する。文字ラティスの例を図1に示す。文字ラティスは、文 字切り出し/文字認識の仮説をラティス構造によって表現するもので、従来は、 言語知識を利用した文字認識後処理[6]に用いられていた。筆者らは、与えら れたキーワードを文字ラティス中から高速に検索する手法を提案し[7]、これ によって、全文検索可能な文書画像データベースシステムの構築を行った。こ のシステムによって「分散」というキーワードを検索した結果を図2に示す。
以下、2章では文書画像からの文字ラティスの生成法について述べ、3章では文 字ラティス中の文字列検索法について説明する。4章では提案手法の評価を行 う。5章はまとめである。
上記で述べた手順は2値画像を前提としているが、筆者らが提案している文献 [11]および文献[12]の手法を適用することで、カラー文書画像に対しても適用 可能である。
上記のアルゴリズムを実装する上で問題になるのは、M-state が集合であり、 M-state の更新が集合演算になることである。M-state をどのように実装する かについては、文献[7]では2つの方法を提案した。一つは、トライ[16]による ものであり、もう一つは、ビット配列[17]によるものである。トライは複数の 文字列を1つの木構造で表現したものであり、ビット配列は有限要素の集合を ビット(0 または 1)の配列で表現したものである。
トライを用いた実装では、多数の文字列を同時にかつ効率的に検索することが 可能であり、文献[7]での実験によれば、1単語を検索する時間の3倍弱の時間 で10000単語を同時に検索することができた。よって、文字ラティス中から辞 書単語を抽出するといった用途に向いている。筆者らは、抽出した単語の共起 関係を利用した文書解析[18,19]などに利用した。
それに対して、ビット配列を用いた実装は以下の点で文書画像の検索に向いて いる。
後者については次節で詳しく述べる。
文献[20]では、通常のテキストに対して、ビット配列を用いて誤りを許す検索 と正規表現による検索を実現している。ここでいう誤りを許す検索とは、k 文 字以下の挿入、削除、置換があっても正解とみなす検索である。この場合、検 索時間は k+1 倍になる。
文字ラティス中の文字列検索についても、文献[20]と同様の工夫で誤りを許す 検索を実現することができた。すなわち、M-state を k+1 個用意し、挿入、 削除、置換を許す演算を順番に k 回行えば、k 文字以下の挿入、削除、置換 が検出できるというものである。また、挿入、削除、置換の重みを変えて検索 することもできる。例えば、挿入と削除を 2、置換を 1 として全部で 2 以下 の誤りを許すと、1文字の挿入または削除、もしくは2文字の置換を許す検索が 可能になる。
正規表現による検索はやや複雑になるので実装はしていないが、同様に実現可 能である。このように複雑な検索が可能になるのは、ビット配列が複数の状態 を保持しながらも演算量は変わらないことによる。
以上の結果から、通常のテキストの 4.02 倍の文字候補ラティスによって、文 字認識率 99.2% の OCR と同等の性能を得ることができると言える。
まず、情報検索の評価によく使われる、再現率と適合率を定義する。
再現率が高いことは、それだけ見つけたかったものが見つかったことを意味し、 適合率が高いことは、見つけたものの中にゴミが少ないことを意味する。
前節の実験で用いた文書を対象として、1位候補のみの場合(通常の OCR と同 様だが切り出しは複数の候補を用いている)、本手法(平均 2.83 候補/文字)、 8候補全て用いた場合(8候補/文字)のそれぞれについて再現率と適合率を求め た。検索すべきキーワードは、かな漢字変換用の辞書から、16234語の名詞(1 文字のもの、平仮名のものを除く)を与えた。結果を以下に示す。
-------+----------------+--------------+------------------
| 再現率(見逃し) | 適合率(ごみ) | 文字認識率(誤り)
-------+----------------+--------------+------------------
1候補 | 81.6% (68) | 99.0% ( 3) | 93.2% (116)
本手法 | 97.8% ( 8) | 87.0% ( 54) | 99.2% ( 13)
8候補 | 98.9% ( 4) | 54.1% (311) | 99.5% ( 8)
-------+----------------+--------------+------------------
なお、() 内は、見つけようとしたが見逃したキーワード数、存在しないが見 つけてしまったキーワード数、文字認識誤りの文字数をそれぞれ表している。
この結果から分かるように、見逃したキーワード数は文字認識誤りの個数にほ ぼ比例しており、文字認識率の向上がそのまま再現率の向上につながっている。 また、候補数を増やすことによって適合率は急激に下がることも分かる。どの 程度の再現率、適合率が必要かは状況次第であるので、状況に応じてこれらの 値を変えられるような枠組みも今後は必要になるだろう。
また、3.2節で述べた誤りを許す検索を行った場合、上記の結果よりも再現率 が向上し適合率が低下するが、特に短いキーワードに対しては適合率の低下が 激しく実用的ではなかった。ある程度長いキーワードに限定する、通常の検索 で見つからなかった場合のみ実行する、などの工夫が必要であろう。
今後の課題としては、再現率と適合率を必要に応じて自由に設定する手法の考 案、誤りを許す検索手法による再現率の向上などが挙げられる。
[2] 杉本: ``ディジタル図書館実現のための要素技術と環境要素,'' vol.37, no.9, pp.820-825, 1996.
[3] Elsevier Science: ``TULIP - The University Licensing Program,'' http://www.elsevier.nl/homepage/about/resproj/tulip.shtml.
[4] ソフトバンク技研, 大原: ``徹底比較! 日本語 OCR ソフトウエア,'' DOS/V Magazine, Technical Test Labs, 5.1, 1996.
[5] 村瀬, 若原, 梅田: ``候補文字ラティス法による枠無し筆記文字列のオン ライン認識,'' 信学論, vol.J68-D, no.4, pp.765-772, 1985.
[6] 村瀬, 新谷, 若原, 小高: ``言語情報を利用した手書き文字列からの文字 切り出しと認識,'' 信学論, vol.J69-D, no.9, pp.1292-1301, 1986.
[7] Senda, S., Minoh, M. and Ikeda, K.: ``Fast String Searching in Character Lattice,'' Trans. on IEICE, vol.E77-D, no.7, 1994.
[8] 美濃: ``文書画像処理の現状と動向,'' 信学会誌, pp.502-509, vol. 76, no. 5, 1993.
[9] Senda, S., Minoh, M. and Ikeda, K.: ``Document Image Retrieval System Using Charcater Candidates Generated by Charcater Recognition Process,'' Proc. of 2nd ICDAR, pp.541-546, 1993.
[10] 孫, 田原, 阿曽, 木村: ``方向線素特徴量を用いた高精度文字認識,'' 信学論, vol.J74-D-II, no.3, pp.330-339, 1991.
[11] 久保, 美濃, 池田: ``カラー文書画像からの写真領域抽出手法,'' 第48 回情処全大, 2-41, 1994.
[12] 仙田, 美濃, 池田: ``文字列の単色性に着目したカラー画像からの文字 パタン抽出法,'' 信学技報, PRU94-29, 1994.
[13] Boyer, R. S. and Moore, J. S.: ``A Fast String Searching Algorithm,'' Comm. of the ACM, vol.20, no.10, pp.762-772, 1977.
[14] Aho, A. V. and Corasick, M. J.: ``Efficient String Matching: An Aid to Bibliographic Search,'' Comm. of the ACM, vol.18, no.6, pp.333-340, 1975.
[15] Knuth, D. E., Morris, J. H. and Pratt, V. R.: ``Fast Pattern Matching in Strings,'' SIAM J. Comput., vol.6 , no.2, pp. 323-350, 1977.
[16] Aoe, J.: ``Computer Algorithms -- Key Search Strategies,'' IEEE Computer Society Press, 1991.
[17] Baeza-Yates, R. and Gonnet, G. H.: ``A New Approach to Text Searching,'' Comm. of the ACM, vol.35, no.10, pp.74-82, 1992.
[18] 津田, 仙田, 美濃, 池田: ``自動作成された単語間リンクによる検索質 問作成支援,'' 第48回情処全大, 1993.
[19] 仙田, 美濃, 池田: ``文書画像を対象とした未知単語の抽出法,'' 第48 回情処全大, 2-15, 1994.
[20] Wu, S. and Manber, U.: ``Fast Text Searching Allowing Errors,'' Comm. of the ACM, vol.35, no.10, pp.83-91, 1992.
図1 文字ラティスの例
図2 「分散」を検索した例
{kind=link}
{kind=link}