我々は誰でもがどこからでも必要な情報にアクセスできるディジタル図書館 『ユニバーサル図書館』構築の要素技術として既存図書の電子化遡及入力のた めのシステム「情報ファクトリ」を提案する。本システムは図書のスキャナ入 力、OCR、構造化、データベース蓄積を統合的なシステムとして提供するこ とで図書の電子化を容易にすることを目標とするものである。
NEC Corporation, Kansai C&C Research Laboratories
1-4-24 Shoromi Chuou-ku Osaka, 540, JAPAN
Phone: +81-6-945-3213, Fax: +81-6-945-3096
E-Mail: {kamiya, daimon, ishidakz}@obp.cl.nec.co.jp, segawa@mech.cl.nec.co.jp, noboru@pat.cl.nec.co.jp, nami@swl.cl.nec.co.jp
We propose and develop a integrated digitaizing system ``Information Factory'' for a part of digital libary concept ``Universal Library''. it integrates scanning process, OCR process, structurizing process and storing process and it aims at easily digitizing documents for non-professional computer users.
これらの研究領域にうち、検索手法に関しては、我々の研究[市山96],[神谷 95]などを含め、国内外で多くの研究が行なわれている。また、ネットワーク 技術に関してもマルチメディアデータの流通を可能とするATMなどの高速なネッ トワークシステムの研究が行われている。これに対してデータの入力手法に関 しては電子図書館では既に電子化されたデータを対象とする場合が多く、既存 の図書を検索のために遡及的にデータ化する研究は比較的少ない。[石川94]
しかし、現在の図書館に蓄積されている情報のほとんどは紙、書籍の形であり、 これらの情報を電子的に検索、閲覧可能とすることの意味は小さくない。我々 は、大学、企業の研究者による研究、調査のための図書館、公共の図書館を日々 利用するような一般の利用者のための図書館などを統合し、ネットワーク上の ディジタル情報として流通させることを目的としたユニバーサル図書館につい て検討、試作を行なっている。本稿ではそのなかで、既存の資料のディジタル 遡及入力のためのシステムである「情報ファクトリ」の検討と試作について報 告する。
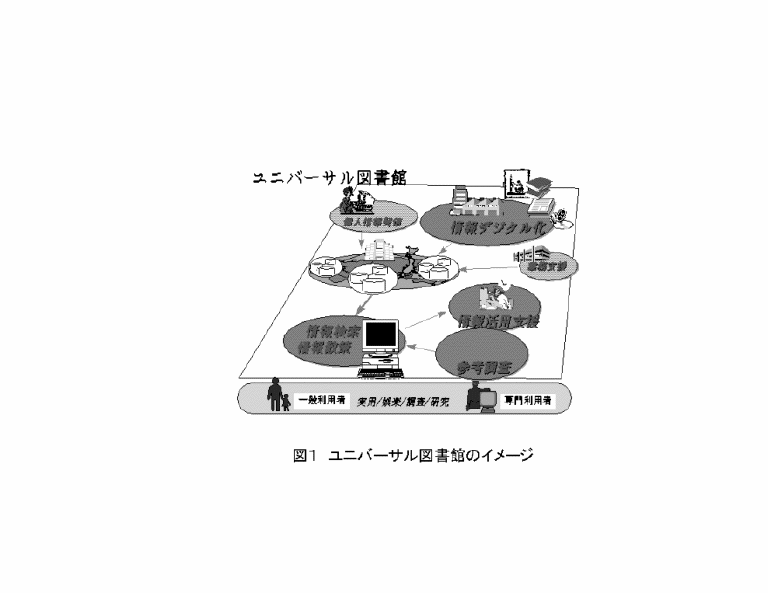
ディジタル図書館全体をネットワークを介してディジタル化された情報をどこ からでも誰でもが閲覧、利用することができるようにするシステムとした時に、 ディジタル専門図書館とディジタル一般図書館の特色は以下のように想定され る。
・ディジタル専門図書館
- 研究利用などの、情報の高度な利用
- 利用者層は研究者など特定のグループ
- 蓄積するデータは論文、特殊な文献等
- ユーザインタフェースは効率的な検索用を主目的
・ディジタル一般図書館
- 情報消費利用の場
- 利用者層は一般の市民
- 蓄積するデータは一般的な書籍、ビデオなど
- ユーザインタフェースは操作が容易で情報の閲覧を主目的
この2種類のディジタル図書館のうち、今後まず実用化されていくのは専門図 書館であると考えられる。
これはディジタル図書館の基盤となるのはディジタル情報を流通させるネット ワークであり、現在、急速な普及を見せているインターネットにおいても、情 報取得のために要する時間や利用するためにかかる費用の問題のため、一般の 市民に普及しているとは言い難いためである。
このため、ある程度の費用負担をしてもディジタル図書館を利用することにメ リットのある層がディジタルドキュメント(インフォメーション)デリバリーと してのディジタル図書館を利用するようになると思われる。
これに対して、現在の公共図書館の役割を持つディジタル一般図書館はインター ネットなどのネットワークが広く普及した後に、行政などのサービス機能とし て安価(無料)での市民へのベーシックな情報サービスとして提供することが考 えられる。この場合の形態としては単に現在の図書館の置き換えだけではなく、 現在の博物館や美術館などうち、一般に市民に利用されている部分を含むマル チメデァアサービスとして提供される。
これらの全体を含めたディジタル図書館利用のイメージを図1に示す。我々は これら全体を含む誰でもが使うディジタル図書館像をユニバーサル図書館と呼 び、各サブシステムの検討・試作を行なっている。
我々はディジタル図書館での要素技術としての情報ディジタル化においてまず、 ディジタル専門図書館の既存文書遡及ディジタル化を対象としたシステム「情 報ファクトリ」の開発を行なっている。[大門96]
「情報ファクトリ」では、書籍、雑誌、文書など紙に印刷されたもの(「紙文 書」)を全て「ディジタル文書」化する入力工場を開発することが目標である。 紙文書をディジタル化し、再利用が可能な情報とするには、スキャナによるディ ジタルイメージ入力、レイアウト解析/文字認識、構造化、蓄積の各手順を経 る必要がある。これらの処理を行い、文字情報は電子的なテキストとして、画 像についてはディジタル画像として保存する。また、論文、書類、書籍はその 中に、章や節といった構造をもっており、この構造情報を再構成する処理を行 う。また、紙文書内の文字、画像等のレイアウト情報についても蓄積する。
情報ファクトリでは現在、専門図書館で扱われているような文書(雑誌、文献、 新聞等)を大量に入力することを目的とし、システムの利用者(入力作業者)は 必ずしもコンピュータによる作業に慣れているとは限らない。このためシステ ムは以下のような特徴・機能を持つ。
・ 統合システム
- スキャナ入力から蓄積までの各プロセスを統合して一括処理できるよ うにする。
- 幅広い対象を(単行本、文庫本、論文、特許等)をカバーする。
- 様々な検索方法(書誌事項、レイアウト等)に対応する。
・ 入力作業のナビゲーション
- 作業状況を常に画面上に表示し現在の作業をナビゲートする ユーザインタフェース。
- 煩雑な各モジュールのパラメータ設定を一括して行なえるように し、自動的あるいは容易に適切なパラメータ設定が行なえるようにする。
・ 分散/協調環境での入力作業
- 大量の文書を入力するためには、多地点にある入力作業環境で 入力対象を分担して入力することが必要になると考えられる。
- 入力の各プロセス自体も各モジュール、入力作業が効率的に行なえるように 各プロセスの所要時間に比例して、複数のマシンで協調的動作するシステ ムとする。
試作したシステムの構成を図2に示す。ハードウェアはパソコン1台に入力機器 を接続した構成である。(データベースはネットワークを介して別のPCを利用 することもできる。) 全体制御部が、各モジュールを管理する形態をとり、各 モジュールのパラメータの起動、データの受渡しを行なう。
情報ファクトリでは以下に示すような手順で図書のディジタル化入力を 行なう。
以下では、各部の機能と特徴について述べる。
このため、情報ファクトリのスキャナ入力としては、通常のフラットベッドタ イプのスキャナおよびデスクスタンドタイプのスキャナを接続して用いている。 このうちフラットベッドスキャナはWindowsでの標準的なスキャナインタフェー スであるTWAINを用いており、TWAIN対応の各種スキャナが利用可能である。フ ラットベッドスキャナではカラーの表紙画像、背表紙画像などを高精細に入力 することができる。また、本文ページの入力においては、書籍の見開きページ の入力が可能であるデスクスタンドタイプのスキャナ[柏谷95]を利用する。 (図3)
デスクスタンドスキャナは通常の見開きの原稿をそのまま入力可能であり、 「紙文書」のうちに特に書籍の形態のものを分解せずに容易に入力作業が可能 であるという特徴を持つ。また、より大規模な入力には自動給紙機構を持ち、 ページの裏表入力の可能なスキャナの利用が考えられる。
スキャナのパラメータは全体制御部の指示によって設定され、入力されたディ ジタルイメージは文字・レイアウト認識部へ送られる。
本システムの文字・レイアウト認識部では従来の手法に比べ、以下の2点につ いて改良を行なったシステムを利用している。
・ 動的二値化方式
デスクスタンドスキャナ入力画像に見られる背景部の照明むらに影響されない 2値画像を生成するため、新規に動的二値化を導入した。(図4)
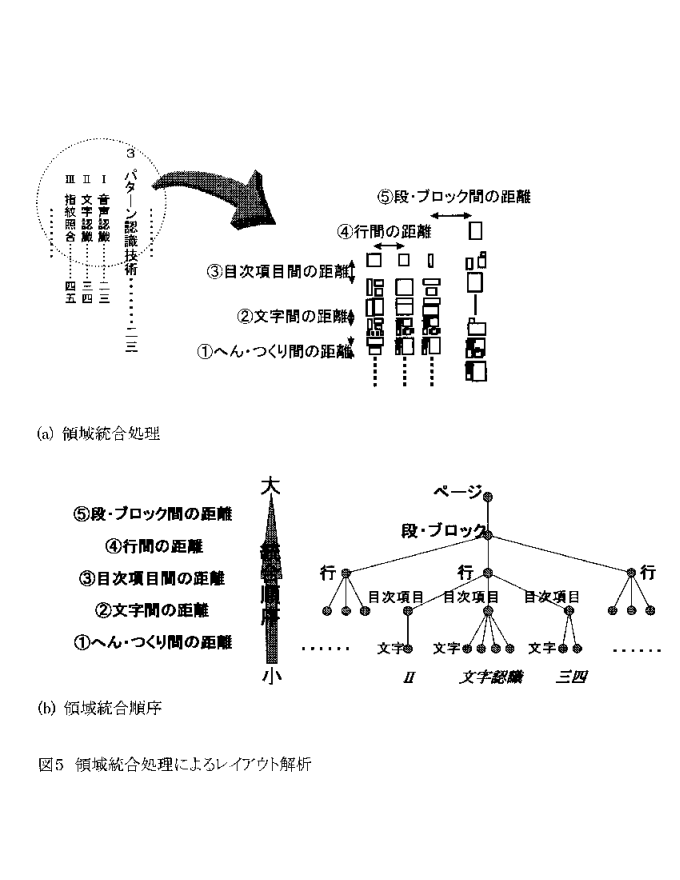
・ レイアウト認識では従来、文書画像の水平・垂直方向への過疎を投影し、 投影パターン上での空白を検出することで領域分割を行い、文書のレイアウト 構造を抽出していた。[辻91]しかし、この方法では文書の傾き、周囲に現れる ノイズ、囲み枠が存在する場合にレイアウト解析が行えない。そこで、文字の 辺、旁の間隔、行間距離等のレイアウト上の規則に基づいて、統合して行く処 理に基づくレイアウト解析を行なう(図5)
レイアウト認識部では、各ページの文字、行などの領域構造を抽出し、文字領 域と図表領域の分離を行なう。このレイアウト情報と、文字認識結果の組が全 体制御部に送られる。
全体制御部では、一文書を単位としてレイアウト情報と文字情報をまとめて文 書構造化部を呼び出す。
既存の文書を電子化して保存する場合には、文書を単にイメージとして保存す るのではなく、文書の持つ文字情報を計算機可読なテキストに変換することに より、テキストの全文検索などの各種の検索が可能となる。さらに、文書、特 に例えば議事録、論文などのように定型的なレイアウト、構造を持った文書に ついてその論理構造を抽出することで、構造を利用した検索が行なるなど電子 化による特徴をより生かすことができる。
・ レイアウト情報の利用
「紙文書」は用紙中への文字や図表それ自身のもつ情報に加えて、 タイトル、章、節などの文章の(階層的な)構造に関する情報を持つ。 さらに、紙面上のレイアウトも文章の見易さや理解し易さに大きな 影響を与える情報であり、重要な役割を担っている。 また、文書の検索の側から見た場合にも、テキスト自身の全文検索や、 文章の章、節の構造に関する検索に加えて、紙面のレイアウトの記憶に よって検索が行なうことが考えられる。
通常、既存の文書のSGML化においては、文書の持つ論理構造のみを記述し、 SGML自身にはレイアウトに関する情報を含めない。しかし、上で述べたように レイアウトに関する検索や、検索後の文書を画面上あるいはプリントアウトし た時に読み易く表示するためにはレイアウト情報についても保存する必要があ る。
本モジュールでは図6のように、通常の論理構造を示すタグに加えてページ中 でのレイアウト構造を示すタグ$<$Layout$>$をタグとして定義し、文章、図表 のブロック(段落)単位でタグ付けを行なうことで検索時にレイアウトによる検 索、表示が行なえるようにしている。
・ 論理構造の抽出
本モジュールでは各ページの文字情報およびレイアウトの情報を入力として、 論理構造の抽出を行なっている。レイアウト情報として利用可能な情報は、 行(文字)の大きさ、行の間隔、インデントなどが利用可能である。文字に関 する情報としてはページ番号、章、節番号部分の数字を利用している。また、 今後、章・節の構造の認識に目次についての認識結果を利用する予定である。
認識手法としては、まず全文を行単位で読み取り、前後の行との相対的なレ イアウト(インデント量等)、行先頭の文字種などにより章・節タイトル、箇 条書項目などのタイプらしさについて各行に評価値を与える。その後、文の 先頭から評価値に基づいてSGMLタグを埋める処理を行なっている。
このうち1,2は、非構造化文書を含めた文書DB一般に要求される機能であるが、 3, 4は、構造化文書の持つ構造情報を利用することによって実現可能な機能で ある。
これらの機能を実現するために、我々はオブジェクト指向データベースPERCIO を利用して、構造化文書を蓄積するためのクラスライブラリを作成した。[波 内96]オブジェクト指向データベースではクラス階層と継承を用い、文書の構 成要素をオブジェクトして管理することにより構造を持つ文書を素直に表現が 可能である。
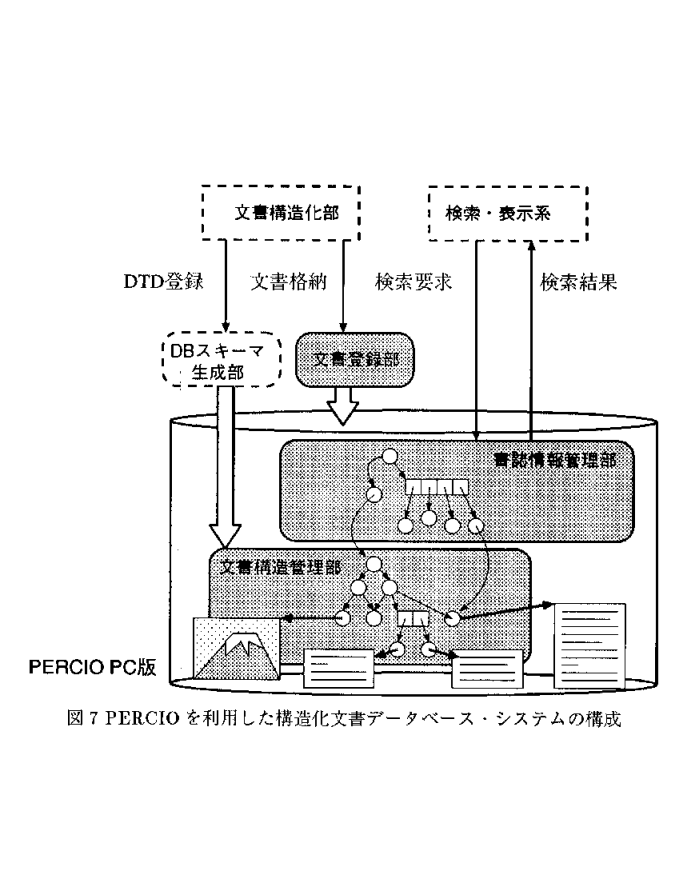
本構造化文書DBシステムは、構造化文書の中でもSGML文書の管理を目的とし、 「DBスキーマ生成部」,「文書登録部」,「書誌情報管理部」,「文書構造管理 部」の4つの部分から構成される (図7) 。これらは、以下の機能を持つ。
以下、本システムの中心となる文書構造管理部について述べる。
文書構造管理部では、SGML文書の内容を実際にDB中に格納する。SGMLでは、文 書の構成要素(文書要素)とそれらの間の関係、すなわち文書構造が、文書型定 義(DTD)によって規定されている。このDTDに則った実際のSGML文書(文書イン スタンス)中では、文書要素の境界をタグで区切ることにより、文書要素とテ キストを対応付けている。
文書構造管理部では、文書の構造情報をDB構造に反映させるために、このタグ で区切られた文書要素ごとにオブジェクトを生成し、そのオブジェクトに文書 の属性、対応するテキストなど、文書要素の情報を格納する。
本システムでは、基本的にDTDのELEMENT定義に忠実にDBクラスを生成する。例 えば、DTD中にELEMENTとして``Document'',``Author''が定義されている場合 には、その構造定義をそのままクラス構造として持つDocumentクラス、Author クラスを生成する。したがってこの方式では、DTDごとに異なるDBスキーマを 生成する必要がある。
この「文書要素対応クラスを生成する方式」を利用することにより、以下の利 点が得られる。
しかしその一方で「DTDが変更されると大幅なスキーマ更新が必要な場合あり」 といった問題点があるが、既存の文書をSGML化する場合にはDTDをあらかじめ 決まっているもとしてほほ扱えるので大きな問題とならないと考えている。
・ 情報入力ユーザインタフェースの設計方針
情報ファクトリは、図書館等における蔵書の大量入力を支援するシステムであ るため、以下の点を考慮してシステム構成とユーザインタフェースの設計を行っ た。
- [スキャナ入力からデータベース蓄積までを統合したシステム] 以下のプロセスを統合し、従来、各プロセス間で前処理/後処理等でデータの 整合をとらなければならなかった点を改善する。
1 入力パラメータ設定
2 スキャナ入力
3 レイアウト解析/文字認識
4 文書構造化
5 オブジェクト指向データベース蓄積
入力から蓄積まで一連の作業を行える統合システムにより、各処理間のデータ 変換などの手間を減少させ、全体をひとつのユーザインタフェースで操作する ことによって、操作性を改善する。
- [入力手順のナビゲート] 利用者が現在の作業内容、状態を把握で きるよう作業状況を常に画面上に表示し、作業手順をナビゲートする。
- [パラメータ設定の簡易化] 利用者の経験等により、入力品質にばらつ きが出にくい、誰が操作しても一定品質が得られるよう、 各処理部での設定パラメータを適切なものに自動的、あるいは簡易的に 設定する機能が必要である。
・ 簡易入力用ユーザインタフェース
情報ファクトリのユーザインタフェースとしては、利用者がスキャナ等の各 種の設定を行なえる「一般入力用インタフェース」と特にコンピュータに不 慣れな人への入力手順のナビゲートを主眼とした「簡易入力インタフェース」 を試作した。以下ではウィザード形式で入力が行なえる簡易入力インタフェー スについて述べる。
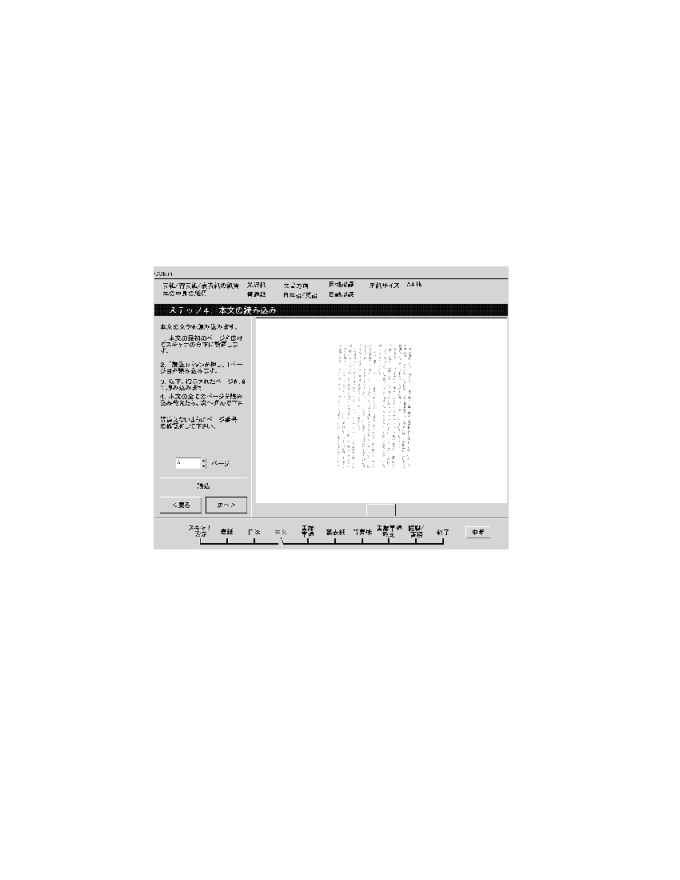
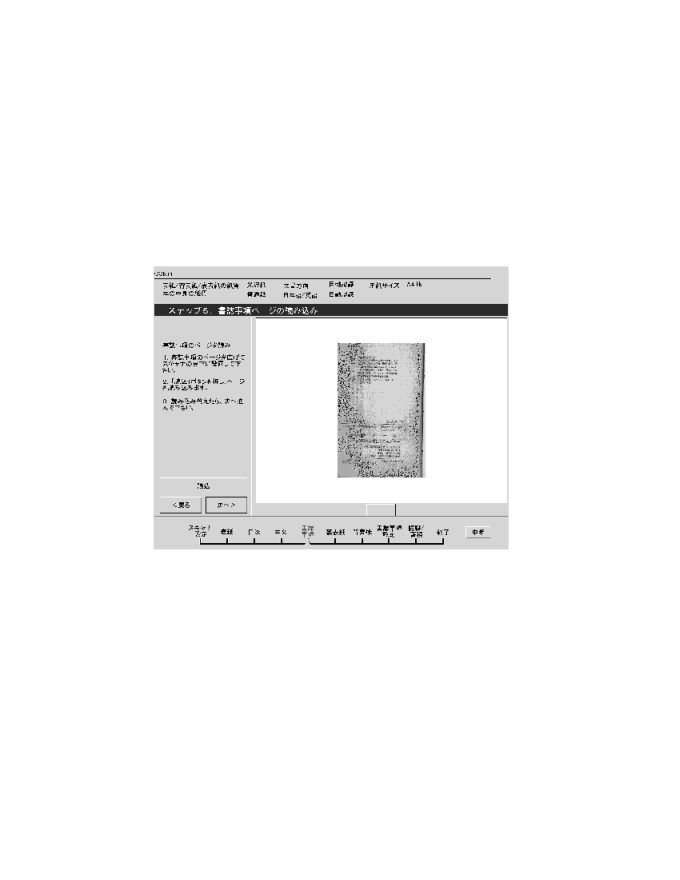
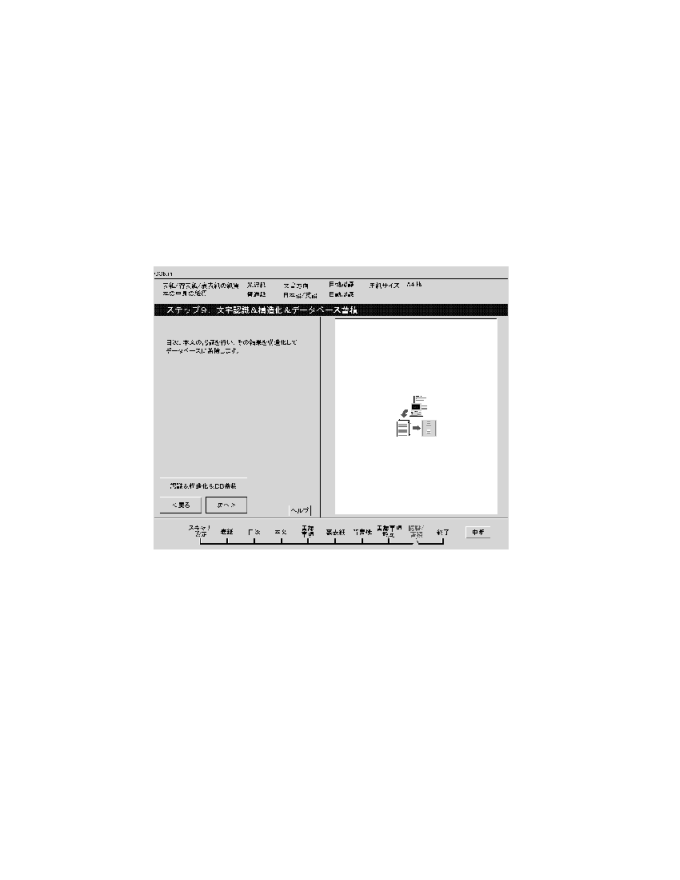
簡易入力用インタフェースはコンピュータに不慣れな人を対象にしたユーザ インタフェースである。入力から蓄積までを、「図書入力ウィザード」に従っ て行えばよいようデザインした。図書入力ウィザードとは、Windowsのイン ストール時に使用されるウィザード等を参考とした入力ガイドである。入力 作業を数段のステップに分け、1ステップずつウィザードに従って操作を行 えば入力作業が完了する仕組みである。画面図を図8a、 8b、8c、 8dに示す。
画面左上にステップ番号を表示し、画面左側に簡単な操作説明と操作ボタン を配置している。ボタンは、「読込」「次へ」「戻る」などで、極力数を減 らしている。「読込」ボタンによりスキャナから画像を入力し、これを画面 右側に縮小表示する。画面下部には入力作業の手順を示し、全体のうち、ど の部分の操作を行っているかを一覧できるようにしている。また、余計な操 作ができないよう画面一杯にウィザードを表示している。
ウィザードのステップは本を表紙から順にページをめくっ て画像の入力を行なった後、書誌情報の設定、認識/構造化/蓄積までを 繰り返す形式になっている。
・ パラメータ設定
入力する本を、その図書の入力に用いるパラメータの共通性から分類し、分類 毎に各モジュールの設定パラメータ情報を持たせることによりパラメータ設定 を簡易化した。各モジュールは例えば本の読み取りサイズ、紙質、使用言語な どによりパラメータ設定を行なう必要がある。同じシリーズになっている書籍 等は同じようなパラメータで入力が可能である。また、よく似たパラメータを 持つ書籍に関してはパラメータセットの一部のみを変更して利用できるように することにより設定の手間を減少させている。
ディジタル図書館実現のためには、検索や蓄積、ネットワーク、データ入力な どの技術的な要素の他に、従来から指摘される、著作権の問題があり、現在の 図書館の所蔵図書あるいは出版社の出版する書籍を本格的にディジタル化する にはしばらくの時間がかかりそうである。しかしながら、今回、検討を行なっ た情報入力のディジタル化は、学会誌、論文誌など著作権の問題が比較的容易 にクリアできそうな
分野や、企業組織、交響団体などでの文書管理システムを手始めとして 着実に普及していくものと考えられる。
これらの分野に対応するためには、今後、今回開発を行なったシステム については、スキャナ部分、文字認識部分などの高速化、高精細化などの 各部の機能向上の他、分散入力環境への対応、実際のユーザの評価に基づく ユーザインタフェースの向上などを行なっていく。また、その他にも高精細 な画像の入力や立体物、ビデオ、音声等のマルチメディアコンテンツの 入力についての開発を積極的に行なっていく必要がある。
また、出版社や新聞社などのコンテンツを持つメディア業種と連携 したシステムの検討、著作権を中心とする知的財産保護に関する研究を 進め、実用的なシステム運用のための技術を確立、実証していく必要が ある。
[柿本95] 柿本 俊博、吉田 哲三,「電子図書館実験システムの開発」, FUJITSU,Vol.46,No.3,pp.276-284,1995.
[藤澤96] 藤澤 浩道、絹川 博之,「「仮想個人図書館」と個人情報 環境」,第6回ディジタル図書館ワークショップ予稿集,pp.11-21,1996.
[高橋96] 高橋 淳一 他,「Global Digital Museum(1) Concept」,第53回情処 全大,Vol.3,pp.423-424,1996.
[市山96] 市山 俊治 他,「多様な情報源を対象とするWWWベース電子図書館シ ステム」,第7回ディジタル図書館ワークショップ予稿集,pp.32-50,1996
[神谷95] 神谷 俊之 他,「3次元ウォークスルーとCG司書を用いた電子図書館 インタフェースの開発」,情報処理学会研究会報告 IM 19-5,pp.27-34,1995.
[石川94] 石川 達也,電子図書館システムとデータ構築 -データ入 力工場設置の必要性-,情報文化学会,マルチメディア分科会 第1回マルチメディ ア研究発表会資料,1994.
[柏谷95] 柏谷 篤 他,平面ミラー回転走査型イメージスキャナ(第2報), 日本機械学会 通常総会講演会論文集(IV),PP. 77,1995
[辻91] 辻 善丈,「スプリット検出法による文書画像構造解析」,信学 論,Vol.J74-D-II,No.4,pp.491-499,1991
[石田96] 石田 和生、市山 俊治,「既存文書のレイアウト情報 付き構造化手法」,第53回情処全大,No. 3,pp.121-122,1996.
[ISO_SGML] ISO 8879,``1986. Information Processing - Text and Office System -Standard Generalized Markup Language (SGML),'' 1986.
[ISO_ODA] ISO/IEC 8613,``Information Technology - Open Document Architecture (ODA) and Interchange Format,'' 1994.
[波内96] 波内 みさ,「OODBによるSGML文書データベースの設計」,情処DBS研 究会第109回予稿集,1996.
[大門96] 大門 秀章 他,「図書構造化入力システム「情報ファクトリ」の提案」, 第53回情処全大,Vol.3,pp.181-182,1996.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}