南俊朗
minami@lib.kyushu-u.ac.jp
九州大学附属図書館
〒812-8581 福岡市東区箱崎6-10-1
Tel: 092-642-2697
Fax: 092-642-2698
我々は,図書目録カードをイメージ化したデータベースを用いることにより,短期間でしかも安価にネットワーク環境における文献検索を実現するシステムの研究を行ってきた. そこでは,データベースの正当性をいかに保証するかが大きな問題となる. イメージ化された直後のデータには,スキャニング作業時に生じたノイズが含まれていたり,重複入力があったり, 更にはインデックス情報のタイプミスなどが含まれていることが多い. 数十万件にも及ぶデータの中から,このようなエラーを全て人手で検出することは,事実上不可能であり,何らかの自動検出機構によるチェックが不可欠である.
本稿では,我々が研究中の目録カードイメージ検索システムにおいて, どのような方法で,イメージデータの画像フォーマットやデータベースの 構成等の正当性チェックを行っているかを,実例を通して説明する. また,これらの方法が,大量データの正当性チェックに関してどのような 示唆を与えるのか考察する.
全国の国立大学図書館には約2億冊の蔵書があるといわれている. 古い蔵書に関するデータ入力作業は国立情報学研究所を中心に全国の図書館が協力し, データの遡及入力が行われてきた. 今後,遡及入力すべき目録カードの数は,全国の大学附属図書館全体で,3500万件余りと見積もられている. 九大単独では約161万件分である. 手作業による入力コストは,1件につき約810円と見積もられているため,全部で13億円余りもの費用がかかる計算になる. また,入力されるデータ数は年間6〜7万件程度である. このペースで入力作業を進めていくと, すべての入力作業を終えるのに約25年もの歳月を必要とする. それまでは従来から用いられてきた図書目録カードから検索する他ない.
このような遡及入力に対処する方法として我々は,図書目録カードをテキストデータ化するのではなく, 高速イメージスキャナを用いてイメージデータ化し, これらを対象とした安価で早急な蔵書検索システムを開発した[1,2]. 目録カードのイメージデータ化は1件あたり10円にすぎない. データすべてのイメージデータ化は約1610万円ですみ, 手作業の約13億円と比較して非常に低コストで実現できる. また,そのイメージデータ化の作業は,1日あたり1万件以上処理可能な 高速イメージスキャナを用いることができるため, 遡及入力すべきデータすべてを数ヶ月程度で処理できる. これもまた,手作業の25年と比較し極めて短期間である. これらのメリットの他にも,イメージデータ化により遡及入力作業が図書館外でも可能であり, 入力作業の効率化も期待できる.
このデータベースは目録カードをイメージ化しただけなので, 遡及入力したデータとは異なり, OPACシステムによるキーワード検索にかけることはできないが, 遡及入力の効率化やOPACとの補間的な検索システムの関係をつくることができることも 大きなメリットの一つである.
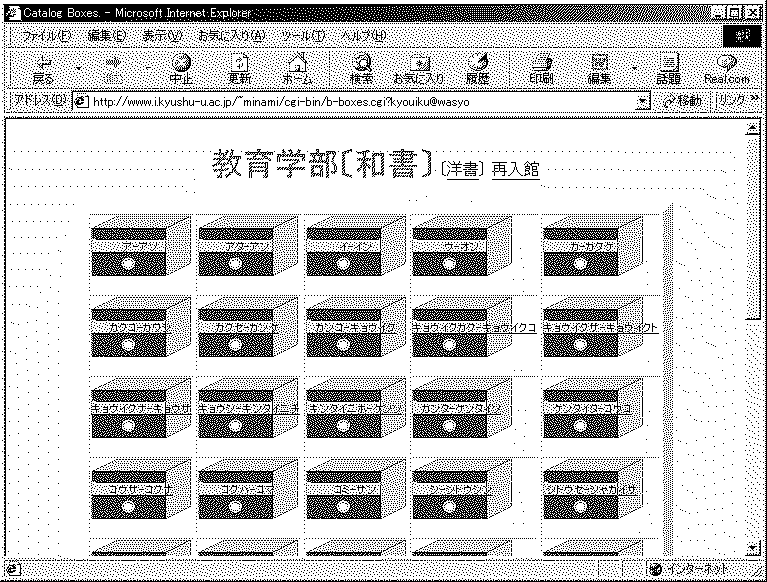
図1. イメージ検索システム: カードボックス一覧画面
九州大学において理学と教育学部,そして文学部の合計約54万冊分の図書目録カードの イメージデータによる目録カード検索システムが公開されている. 本システムを用いることにより, 実際に図書館に行ってカードを探す場合と同様に検索を行うことが可能である. 利用者になじみのある図書目録カードの検索と同様の方法を模倣した 画面上で操作するもので,直観的に扱いやすいよう考慮されている.
図1に教育学部和書のイメージ検索用の画面を示す. 利用者はここで検索したい文献の目録カードの入っているカードボックスを 選び出し,クリックする. すると,図2のような画面が現れる.

図2. イメージ検索システム: カード閲覧画面
左側では箱の中身が表示され,右側には引き出し内のカードが表示される. 左側の目録カード位置をクリックすると,右側にクリックした箇所の前後のカードが現われる. 右側部分のボタンにより前後のカードへ移動できる. イメージカードを用いた検索システムは九大の他にもいくつか存在する. 例えば,Virginia図書館[3]においては,図書館収集の資料に関して, その目録カードをイメージ化したカードの元資料の詳しい情報や中身にリンクさせていて, Web上で資料の一部ないし全部を見ることができる. Princeton大学図書館[4]においては,1980年以前のデータに関して カードのイメージ化を行っている.それ以降のものはOPACで検索するようにと 切り分けておらず,遡及入力なしで,新旧のカード検索が実現されている. 慶応義塾大学図書館[5]では,中国・朝鮮・アラビア・ロシア語資料に対する 検索システムとして,読みのアルファベット表記による検索システムと連携し, 検索された内容をそのカードイメージにより詳細に確認できる. いずれも,イメージ化データを用いた検索システムで, それぞれ違う視点からの工夫がなされている.
・ 1日1台当たり1万枚以上入力可能な高速スキャナーを用いて図書目録カードを入力する.
・ 入力は,カードボックス,およびその中にある仕切りカードを区切りとする単位で行われる.
・ 各カードブロックは仕切りカードに記載されたラベルによって識別される.また,1つのカードボックス内のカードブロック全体は,カードボックスラベルによって識別される.
・ それぞれの学部におけるカードボックス群は,和書,洋書等の言語によって分類されている.これらの分類を考慮し,読みこまれたカードイメージ全体は,学部/和洋分類/ボックス/仕切り/イメージという階層構造の中に配置される.
このような作業の際に考えられる誤りとして,カードの束をボックスから取り出す際に, カードを取り落としたりする物理的取り扱いのミスによるエラー, カードスキャナーの不調や読み取り設定ミス等によるデータ読み取り時のエラー, そして,手入力される,カードボックスや仕切りカードのラベルの入力エラー等が考えられる. また,スキャニングされた,これら多数の図書目録カードデータを画像検索システムに対するデータベースとして使うためには, それらを仕様に合うように適切に配置する必要がある.その際のエラーも考えられる.
これらのエラーを検出し,修復するために, イメージデータフォーマットや,画像データベース構造の正当性を検証することは, システムを稼動させる前段階として重要な仕事である. しかし,この目録カードデータベースは人手によって検証するには,あまりにも巨大であり,事実上不可能である. そのため,データベースを読みだし,エラーチェックを行うプログラムによる自動検証が唯一可能な検証手段である.
本節では,図書目録カードのイメージ検索システムにおける文学部の目録カードデータベースについて行った検証作業に関して,その内容及び結果を報告し,正当性の自動検証作業に関する考察を行う.
文学部の目録カードデータベースの具体的構造を図3に示す. データの階層構造の一番上にbungakuという名前のディレクトリがあり,これが文学部データのルートとなっている. ルートのすぐ下にはwasyo, yousyo, RUSSIANの3つのディレクトリがあり,それぞれ和書,洋書,ロシア語の分類項目を意味する. それぞれの下に辞書順でボックス識別名が配列されている. さらにその下にはカードボックス内をさらに細分化する仕切りカードの識別名が配列されている. 各仕切りの中に,画像データが1から順に通し番号をつけられたTIFFファイルとして収納されている. ボックスと仕切りカードそれぞれのディレクトリには,それらに対して表示されているラベル文字列が,テキストファイルとして置かれている.
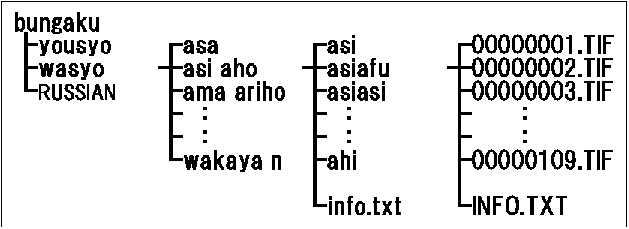
図3. 文学部目録カードデータベースのディレクトリ構造
文学部のデータは約384,700個のファイルからなり,約3.33GBの容量である. これらのデータ群を検証するための検査項目を,次の2つに大別する.
・ イメージデータ群の構造上の誤り
・ イメージデータのフォーマットの誤り
なお数十万件ものデータ群を扱うため,図書目録カード群の正当性検証にかかる時間も無視できない. 以下,それぞれの検査項目に関する詳細な説明を行い,その結果と検証時間を示す.
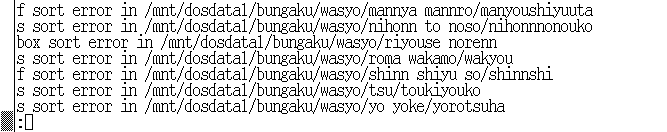
図4. 和書の辞書順チェック

図5. 洋書の辞書順のチェック
和書・洋書の構造が辞書順かどうかの検証を行った.図4及び図5にその結果の一部を示す.図4の3行目に
wasyo/riyouse norenn
という行がある.これはリヨウセからノレンまでの目録カードがこのカードボックスに含まれる という表示である.しかし,これはカードの順序としては正しくない. また最下行の
wasyo/yo yoke/yorotsuha
においても,ヨとヨケの間にヨロツハという仕切りが入っているが, この仕切り項目はカードボックスに表示された範囲に含まれていない. こういった間違いが全部で160箇所発見された.
図5に示した洋書検証データ最下行の
yousyo/ba bak/b
についても,baとbakの間にあるbという仕切りは辞書順の並び上誤りであるとの 判断に基づいて検証プログラムが表示したものである. 実際,bという表題の本は考えにくく,ここのカードボックスには bの次のba以降の辞書順に目録カードが並んでいると考えられる. このように考えると,このディレクトリ名はまちがっておらず, 人間の手による目録カード検索であれば不都合がないため, この間違いには気付きにくいものと思われる. この洋書の場合の検出結果は,人間が検索することと計算機が検索することの 根本的な違いからくるものと考えられる.
なお,これらのエラーに対しては,仕切りカードの下にある目録カードを実際に調べることにより, 仕切りラベルの誤りであるのか,もしくは,ラベルは正しく,その置かれているカードボックスが誤りであるのかを判断し,対処することが必要となる.
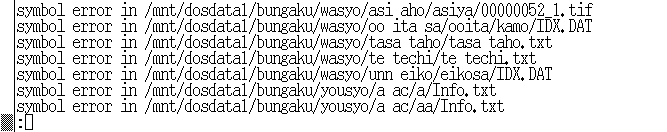
図6. ファイル名のチェック

図7. ディレクトリ名のチェック
ボックス名及び仕切り名のディレクトリ中にはINFO.TXTまたはinfo.txtというファイルが存在することになっている. しかし,実際に検証してみると,ディレクトリの一部において, その名前が間違って記されているものや,全く存在しないものが発見された. それらに関しては,ファイルを追加するなり,正しい名前に変更する,といった処置が必要となる. 具体例としては,図7に見られるように,名前が間違ってInfo.txtやte techi.txtなどと記されているものが見つかった. また図7に見られるように,ディレクトリの名前に()や'などのアルファベット以外の文字が使われている箇所があった. その他にも空白が2つ続く場所や,アラビア数字の代わりとしてviやviiなどと記されている箇所もあった. 特殊な文字をディレクトリ名やファイル名として用いると,検索システム実装の際, バグを誘発する原因となることが考えられるため, そのような問題の起こらない通常の文字を用いた名前に変更するのが望ましい.
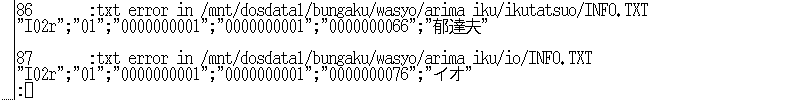
図8. INFOファイルの中身検証その1

図9. INFOファイルの中身検証その2 info.txtまたはINFO.TXTというファイルの中には, このファイルが入っているイメージボックス,もしくは仕切りの ラベルを示すテキストが入っていることになっている. しかし実際には,テキストが何も無い箇所や,図8の最下行にあるようなタイプミスによる誤ったデータが入っている箇所がある. ラベルの中身に関しても, ローマ字(図8の1, 2行目),漢字(図9の1, 2行目),カタカナ(図9の3, 4行目)の3通りの記述があり, 改行コードがつけられているものとないものと様々である.
wasyo/oo ita sa/ooita/kamo/
wasyo/oo ita sa/ooita/kannkokusu/
というディレクトリが存在し, そのディレクトリの中に画像ファイルとinfo.txtがあるという構造が発見された. このタイプのエラーに関しても,画像の内容を確認することにより,適切な仕切り名を見つけ, それを適切なボックス内に置く処理を行うことになる.
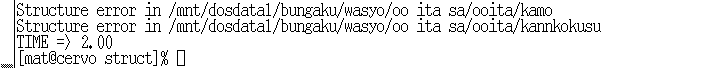
図10. ディレクトリ構造の間違い

図11. 穴の位置の間違い
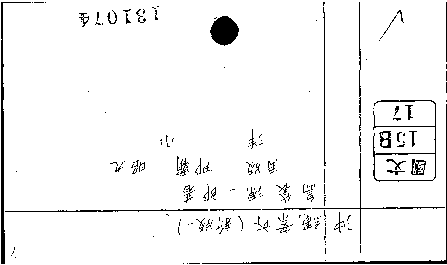
図12. 回転したカード
調べた結果6つの回転画像ファイルが検出された. 検出された目録カードの例を図12に示す. なお,穴のないカードとして検出されたものを確認してみると, 穴のないカードと穴が小さすぎて穴として認知されなかったカードが検出されていた.

図13. 検証にかかった時間
次に目録カードの分類基準に統一されたフォーマットがなく,分類者の主観に起因するカード配置のゆれが原因の一つとして考えられる. 従来の目録カード検索システム自体には大まかなフォーマットが存在したが, 例外としてのいくつかの規格外のフォーマットや構造があり, このことが後にこの目録カードから作られたイメージデータ群から 検索システムを構築することを難しくしていると思われる.
例えば図5において, 洋書のau azのカードボックスの部分に注目すると, 上にadded entry cardsという仕切りがあり, 更にconfessionesからworksまでの仕切りがある. これはau azの箱にはauから次のaz以前のものが 入っていて欲しいのだが,そうはなっていない. こうなる原因として,原則的には辞書順列でカードは並んでいるのだが, 分類上,特定の書物に関してまとめてしまったほうが探しやすいと判断され 特殊な分類をされたカード群が存在することが考えられる. 人の手による検索を行ったとき, このカード群に属さないカードは,普通に目録カードを検索する要領で発見できるため, 特殊な分類をされているカード群の存在に気付かずに目録カード検索してきたが, 今回の,目録カードのイメージデータのデータベース化で問題のカード群の存在が 明るみになったのである.
これまでの目録カードの仕様というのは, 計算機上にイメージデータ化されることを考慮しておらず, 人の手で検索するのに都合のよい分類・収納になっている. 計算機の都合のよい分類・収納というのは, ある規則に従ってソーティングされたデータ群であり, 規則の例外は,個別に処理しなければならない. 規則は簡単明瞭であればあるほど望ましい. 例えば,ローマ字表記は同音異表記できる.tiもchiも人間には「ち」だが 計算機に分かりやすいようchiに統一する,という具合に, 表記方法をシステムで統一することは作業のスピードアップや簡略化につながる. さらにデータ参照の都合が良くなることはもちろん, 他のシステムへ移植する際に表記方法を変える必要性が でてきたときに容易に変換できるという利点もある. この問題は人手による検索を想定した仕組みをそのまま機械化した場合, 常に起こり得る深い問題を示唆しており,今後の大きな研究課題である.
巨大データベースの検証の困難さについて考察する. データ群に対して検証を行う,ということは 人間の予想する範囲の規格外のミスを検出することにより 修正がなされていく. つまり,完全なデータ群を構築するのは 予想する範囲のミスを取り除くことはできるが, 予想外のミスの発見に対しては,偶然に発見されるのを待つしかない. このことは巨大なデータベースの検証の難しさを表している. 大量のデータベースの正当性について検証は,人手では 不可能なため,コンピューターによる検証を行うことになる. しかし,考え得る検証項目を洗い出し,それを発見するプログラムを組み,調べていくという 方法論を取るため,最終的に完全なデータベースが 出来上がったという保証を得ることはできない. 予期せぬ出来事があり,検証項目には引っかからない間違ったデータが あるかも知れないからである. 結局のところ,大量データの検証は考え得るあらゆるエラーに対処しつつも, それ以外の新種のエラーが発見された場合を想定し,それが起こった場合, 速やかに対処できる手立てを整えておくことが最善の対処法であると思われる.
九州大学では,附属図書館所蔵の文献に関する書誌情報検索機能をネットワーク を通じて提供する図書目録カードイメージ検索システムを開発し,公開してきた. このようなシステムの信頼性を確保するためには,プログラムの信頼性を高める のみならず,データの正確さも要求される. 本システムの場合,対象となるデータ数は全部で約54万件にも上るため,人手 でその正当性を検証することは不可能である. そのため我々は,カードイメージの検索システムのためのデータの正当性を検証 するプログラムを開発し,それを用いたデータの検証を行った. 検証は,データの構成に関してと,データそのもののフォーマットに関して の両方を実施し,データ入力時のエラーや補足情報入力時のタイプミスなど, 様々な種類のエラーを発見した. 一部のエラーについては自動的に訂正することが 可能であるが,再入力するなどの手段により,改善せざるを得ないエラーも多い.
大量データの正当性検証に関する我々の経験より,発生したエラーを検出し, 対処するよりも,初めからエラーの発生の少ない方法で,データを生成することが 如何に重要であるかを痛感した. また,エラー発生の原因には,人間にとって使いやすいシステム構成と機械的処理の容易なシステム構成の間のギャップによるエラーの発生も存在しうることが理解できた. これらのことから,人手で作業することにより発生するエラーのタイプを予め完全に予想し, その検出方法を考案することは不可能であり,従って, 新しいエラーが発見された場合に速やかに対処できるよう 柔軟にシステム設計を行うことが,結局のところ,エラーに対処するための最善の方策であると考えられる.
今後の課題の一つは, 検索システムの使いやすさの追求である. 例えば,いくつかの図書館間を連携させたイメージデータ検索システムの構築がある. システムの仕様変更や新しいシステムの追加等に柔軟に対処できるデータベースの存在意義は大きい.
さらに,我々のシステムの適応範囲を九州大学附属図書館以外にも広げていくことも, 今後の課題の一つである.その実現のためには,システムのみならずデータの検証方法に関して,多様な状況に対応することが必要である. そのために,これまでの経験を生かし,より精密なデータの検証方法ならびに 自動的もしくは半自動的にエラーを修復する方法を開発することは, 極めて有益な事である.
なお,2000年11月現在,本検索システムは, http://www.i.kyushu-u.ac.jp/~minami/Card/ で運用中であり,また, 九州大学附属図書館のホームページhttp://www.lib.kyushu-u.ac.jp/ からもリ ンクされている.
[2] Toshiro Minami, Hidekazu Kurita and Setsuo Arikawa: "Putting Old Data into New System: Web-based Catalog Card Image Searching", 2000 Kyoto International Conference on Digital Libraries: Research and Practice, 2000. (掲載予定)
[3] The Library of Virginia: http://image.vtls.com/collections/
[4] Princeton University Library: http://imagecat1.princeton.edu/ECC
[5] 慶応義塾大学図書館: http://catalog.lib.keio.ac.jp/ckabooks/
[6] 栗田英和: "イメージデータ化された図書目録カードの検索システム", 九州大学大学院システム情報科学研究科情報理学専攻修士論文, 九州大学, 2000