Figure 1 - Dienst Service Interaction
The CDLRG (Cornell Digital Library Research Group) is investigating the architectures, protocols, and supporting mechanisms to create component-based digital libraries. This paper describes the nature of that research program.
Any description of a research program should begin by broadly defining the subject of research. Attempts to define the term digital library, however, sometimes resemble the fabled " blind men and the elephant ". I can only claim to be one of those blind men and offer the particular definition on which this research program is built.
A digital library is a managed collection of digital objects (content) and services (mechanisms) associated with the storage, discovery, retrieval, and preservation of those objects. Management has three components:
The use of the term component-based to refine this definition is a reflection of a belief that the architecture of digital libraries should be based on modularity - a well-known software engineering principle. That is, digital library services should be constructed as independent modules, or components, that may be distributed across the Internet and which communicate with each other through open protocols. The advantages of this modularization include customizability, the configuration of services in an individual digital library can be tailored to meet the requirements of the intended user community; ease of refinement, the functionality of individual services (e.g., new search engines) can evolve independently; and extensibility, new services can be developed and integrated into the service infrastructure, and take advantage of the functionality of existing services.
The notion that digital library architecture should enable multiple communities and individuals to tailor information content and information spaces for particular needs is a theme that extends throughout our research program.. This reflects the fact that technical solutions are but one facet of digital library research, and that complex social, political, and economic factors must be considered.
The remainder of this paper describes the research program of the CDLRG in the following areas
This section describes each of the major research areas of the Cornell Digital Library Research Group. The funded projects in which this research is taking place are described in Section 3.
Historically and conceptually the core work of the CDLRG lies in the formulation and investigation of infrastructure to facilitate component-based digital libraries. This work builds on a design framework described in [1, 2].
Work on infrastructure within the CDLRG began with the CS-TR (Computer Science Technical Reports) Project, a DARPA (U.S. Defense Advanced Research Projects Agency) funded effort to examine tools for electronic publication of Computer Science Technical Reports. This early digital library project was a collaboration of the " top five " computer science institutions in the United States: Berkeley, Carnegie-Mellon, Cornell, MIT, and Stanford.
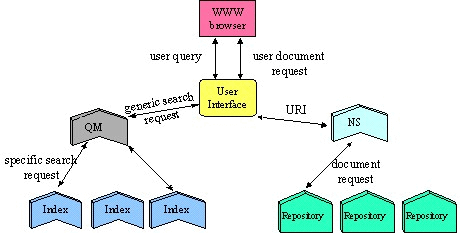
Cornell contributed the mechanism for interoperability in the project, a system called Dienst (Distributed Interactive Extensible Network Server for Techreports) [3, 4, 5]. (Dienst, pronounced denst, is also the Dutch word for " service ".) In the context of our research, the word " Dienst " refers to a number of things:Broadly speaking, Dienst is a system for configuring a set of individual services running on distributed servers to cooperate in providing the services of a digital library. The open architecture of the Dienst system - exposure of the functionality through a defined protocol - makes it possible to combine Dienst services in flexible ways and augment the existing services with other mediator services, which build on the functionality of the existing services.
A complete description of Dienst is outside the scope of this paper, but a brief listing of the features of the architecture is as follows:
Over the past several years, Dienst has provided fertile ground for both practical deployment and as a testbed for research into distributed digital libraries. The most notable deployment of Dienst is as the technical infrastructure for NCSTRL (Networked Computer Science Technical Reference Library) [6, 7], a globally distributed digital library that incorporates content from over 100 institutions. Dienst also provides technology for a number of other collections including CoRR (the Computing Research Repository) [8] and ETRDL (ERCIM Technical Reference Digital Library) [9].
Figure 1 - Dienst Service Interaction
Within the CDLRG, we have exploited the Dienst system and implementation for a number of research investigations. One particular area is distributed searching; mechanisms for determining query routing among distributed search engines [10, 11, 12]. Another research area is the mechanism for creating collections in globally-distributed digital libraries [13,14].
Work on the Dienst architecture, protocol, and implementation is ongoing. We are, at the time of writing of this paper (January 2000), in the final stages of producing a new software release that supports a new version of the Dienst protocol. These new versions considerably enhance the functionality of the Dienst system (e.g., a more powerful document model for structured documents, increased metadata functionality) and improve the modularity of the system. This not only facilitates administration of a Dienst server, but makes the system more amenable for research experimentation (by making it easy to improve and replace service modules).Digital libraries have the potential to represent new types of content and deliver them in innovative ways. Existing digital library research projects and deployed systems give a glimpse of this potential by providing access to digital content in a variety of forms including text, images, video, audio, maps, datasets, and software. The utility of these single medium digital resources is indisputable. However, the rich potential of digital libraries is fully demonstrated by multimedia content that aggregates multiple single medium content streams that are inter-related semantically, structurally, and temporally. The result is digital content that is more informative and more accurately represents physical reality.
Across this diversity of content there is the need for a layer of uniformity among digital resources; a digital object model [15, 16] that provides common high level functionality among all resources regardless of their content. This common functionality includes deposit in and access from repositories, discovery by users and agents, dissemination or presentation of content, and access control for protection of intellectual property. Such high-level operational uniformity allows multiple objects, each with their own idiosyncratic composition and content, to be combined in distributed digital library collections.
While generic uniformity of digital objects is essential to the (inter) operation of digital libraries, there is also the need for functionality that exposes and exploits object specificity. For example, at the most generic level, dissemination from a digital object is simply the output of a stream of bits. At the object specific level, however, disseminations take on unlimited forms unique to the semantics of the specific digital object; for example, the output of a frame from a " video " digital object, a page from a " book " digital object, or a subroutine from a " program " digital object.
In the FEDORA [17] project, the CDLRG is investigating a general digital object model and repository architecture for encapsulating and securing digital library content of all forms and genre. Mechanisms for extensibility are built in to the architecture, thereby allowing individual communities to develop new content types and rights management schemes, yet interoperate in a broad digital library framework. The key challenges we are addressing in FEDORA include:
FEDORA defines a container abstraction known as the DigitalObject that encapsulates multimedia content in typed byte stream packages called DataStreams. The actual byte stream in a DataStream may be local (or internal) to the DigitalObject, or it may be a reference to data external to the DigitalObject (e.g., a result of a GET transaction from an HTTP server). This allows a DigitalObject to be act as a value-added surrogate for other content; a capability which is exploited in our policy enforcement work outlined in Section 2.3.
All DigitalObjects have a set of generic behaviors (the PrimitiveDisseminator methods) to create and access DataStreams and to manipulate the structure of the DigitalObject. The DigitalObject also has an extensible interface layer that provides views, or disseminations, of encapsulated data in a contextually meaningful manner. A dissemination can be a direct transcription of stored data (e.g. a page of a book), any computable derivation of stored content, an interactive object (e.g., a book viewing applet), or any mixture of these. A Disseminator is a FEDORA component that associates an extended set of service requests with a DigitalObject to produce disseminations.
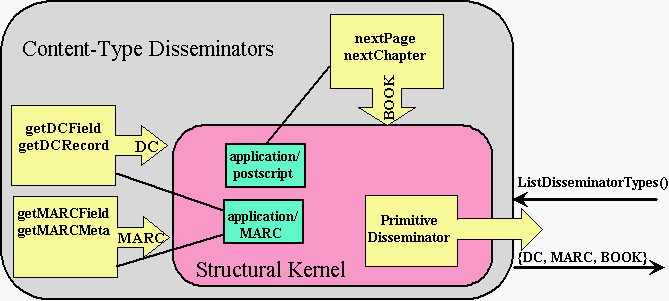
Figure 2 - FEDORA digital object
The architectural segregation of structure, extensible interfaces, and mechanisms for executing extensible behaviors is key to the FEDORA DigitalObject model. Many types of Disseminators can be associated with a DigitalObject to extend its behavior beyond the generic methods. For example, a DigitalObject can have a Disseminator that endows it with a set book-like behaviors, allowing a client to interact with the DigitalObject through a set of requests such as "get next page " or "get next chapter." Each Disseminator references a Signature which is a formal definition of the set of methods that pertain to a particular Disseminator Type. It also references a Servlet which is a mechanism (a program) that executes the methods defined by the referenced Signature. Both Signatures and Servlets can be stored in DigitalObjects and registered with a global naming service (e.g., the Handle System). This creates a de facto registry of Disseminator Types -- Signatures and Servlets become "known " when their names (e.g., URNs of their DigitalObject containers) are registered with a global naming service. A FEDORA Repository provides an environment for activating and running Servlets.
A simple FEDORA DigitalObject is depicted in Figure 2. It contains a structural kernel
with two DataStreams
(a Postscript stream and MARC metadata) and the PrimitiveDisseminator,
which is the set of generic service requests. There are also
three Disseminators
(BOOK, MARC, and DublinCore).
Clients can obtain various disseminations of the DigitalObject
by invoking the methods of each Disseminator.
For example, a client can obtain a Dublin Core record by invoking the getDCRecord()
request. Although there is no Dublin Core data inside this object, the DC Disseminator
activates an external mechanism that derives Dublin Core from MARC data. This
is one simple example of how the underlying structure of a DigitalObject
is distinct from the disseminations it can produce.
Over the past year, the CDLRG has been developing and experimenting with a prototype implementation of the FEDORA architecture. This prototype is implemented in Java and uses the CORBA distributed object model. In our research, the prototype has been used for a range of interoperability experiments [18] with colleagues at CNRI (Corporation for National Research Initiatives). FEDORA will also be used as the basis for experiments with policy enforcement, described in Section 2.3. In addition, a research packaging of FEDORA is available for other researchers who wish to use the implementation for digital library experimentation.
This paper began with a definition of digital libraries that contains the notion of management layered on top of infrastructure. In particular: a digital library infrastructure provides the service definitions, protocols, and digital object model; digital library instances exploit this infrastructure by selecting services and content and administering policies on those selections.
It is illustrative to compare these digital library instances to the current notion of a portal on the Web, for example Lycos, Yahoo, and AltaVista. These portals offer access to distributed content and provide some services over this content (e.g., searching). Yet, there is little argument that these current portals do not provide the level of curatorial responsibility undertaken by existing libraries. The model of a digital library instance proposed here can be thought of as a hybrid portal. It not only expands the traditional portal concept with enhanced services and content (as described in Sections 2.1 and 2.2), but recognizes the need for integrity maintenance (curatorial responsibility) ranging from casual (a distributed e-print archive) to strict and broad ranging (a research library). The effect then is that content and mechanisms may be shared among multiple digital libraries, but the policies applied to that content and services are tailored to the requirements of the organization administering the digital library instance.
Digital library integrity requirements -- for security, preservation, or otherwise -- can be expressed through formal statements called policies. The issue of policy formulation and enforcement for digital libraries is a major focus of the research of the CDLRG. Policy enforcement mechanisms need to be constructed that permit enforcement regardless of the level of control the digital library (the policy formulator and enforcement agent) has over the distributed objects and services. In this context, we are examining the implementation of a policy layer through which each digital library can enforce its policies on the range of content and services and range of control over that content and services.
Libraries, digital or otherwise, formulate and enforce a number of policies. In our research we have chosen to focus on two: 1) security, management of access to content, and 2) preservation, the long-term archiving of content. Research in preservation is addressed more fully in Section 3.1.
The many forms of content in digital libraries offer new challenges for the formulation of security and preservation policies. Two examples from the security domain are illustrative:
In order to understand the effect of these many forms of content in digital libraries, one thrust of our research will be a thorough analysis of security and preservation requirements in the digital library context. This analysis will take into account the diversity of stakeholders that need to be served -- for example, traditional and non-traditional publishers, authors, and the established research library community. It will also consider the impact of the portal model, in which content is distributed and therefore lies outside the control zone [19] of organizations trying to formulate and enforce policies.
In addition to the formulation of security and preservation policies for these new genres of content, there remains the problem of enforcing the policies in a digital library. The mechanisms for policy enforcement in existing computer applications - for example the read, write, and execute access to files and programs that most operating systems implement - are some distance from those required to enforce the complex policies we envisage in digital libraries. The prudent course in designing a digital library architecture is to provide support for an extremely wide variety of security policies. Our intention, therefore, is to take enforceability as the only hard constraint on what policies are allowed, and build mechanisms based on a formal notion of enforceability.
We base our research in this area on a formal definition of enforceability for a class EM (for Execution Monitoring) [20] of policies that can be enforced using mechanisms that work by monitoring (any aspect of) system execution. The execution steps monitored may range from fine-grained actions (such as memory access) to higher-level operations (such as method calls) to operations that change the state of an object and thus restrict subsequent execution.The formal definition of EM is outside the scope of this paper. As a substitute, a few examples will suffice. All known hardware and operating system-based mechanisms, such as those alluded to earlier that restrict access to files, are in EM. The policies discussed above for the survey database are instances of such EM-enforceable access control policies. Rights management policies discussed in connection with electronic documents [21] also fall into this class. A few examples outside the scope of EM are also illustrative. Policy enforcement mechanisms that use more information than becomes available only from observing the steps of a target's execution are, by definition, excluded from EM. Information provided to an EM mechanism is thus insufficient for predicting future steps the target might take, alternative possible executions, or all possible target executions.
Given this notion of enforceability, our research is then proceeding on two tracks:
In addressing the two issues, we will exploit on-going work at Cornell in new policy enforcement mechanisms. All EM-enforcement mechanisms can be viewed as implementing an automaton that makes a transition each time the target system does and that causes the target system to halt if ever an action is being attempted that does not comply with the policy being enforced. Practical realizations of this abstraction are thus based on three mechanisms:
There must be a way for the enforcement mechanism to trigger events in the target system (e.g., when the security policy is about to be violated access to a digital object should be terminated).
We are currently experimenting with these policy enforcement mechanisms in the context of our FEDORA digital object model. The assumption is that we can build digital library specific " policy enforcement layers " by creating digital object surrogates for distributed resources. As described earlier, the DataStreams " contained " in a DigitalObject may, in fact, be remote data disseminated by other digital objects or, in fact, from any other protocol transaction (e.g., HTTP). Thus, it is possible to, in a sense, " impose " policies on external objects. For example, we can build a surrogate digital object that serves as a preservation monitor (that implements some preservation policy) for some external content and that triggers notification events in defined cases (e.g., when conversion of an object is necessary due to a new software version). FEDORA digital objects then become policy carrying containers, in addition to content and behavior carrying containers as described in Section 2.2. This concept is illustrated in Figure 3, which shows a simple digital object containing a policy statement and reference content available through an HTTP GET. A disseminator is associated with these DataStreams that enforces the policy on the remote content (e.g., sends an alert when a preservation state change occurs).
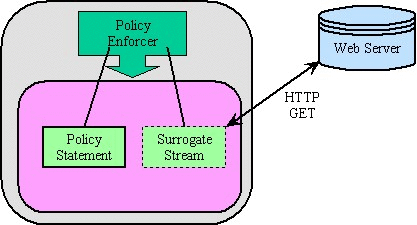
Figure 3 - Policy Carrying Object
An important related issue of this research is the tension between varying levels of control over distributed content and services and the types of policies that need to be enforced. For example, it may be necessary to " assert " full control over an object in certain situations in order to achieve certain policies (e.g., copy the object locally to ensure its full preservation).
The work of the CDLRG in metadata interoperability builds on several years of active participation in the DCMI (Dublin Core Metadata Initiative). Our primary interest in DCMI has been the role of the Dublin Core Element Set in a broader metadata fabric. This is the issue addressed by the WF (Warwick Framework) [22, 23], which describes a container architecture for associating multiple metadata vocabularies (packages) with digital objects. We note that this container architecture and subsequent work on it [24] provided the foundation for the FEDORA architecture.
The motivation for the WF is the belief that metadata should be modular -- individual communities should create and maintain metadata vocabularies appropriate to their areas of expertise. For example, whereas bibliographic metadata should be created and administered by the information management (library) community, metadata governing terms and conditions for access should be the jurisdiction of the rights management (legal) community. This modularity encourages metadata communities to scope their individual efforts and encourages them to avoid attempts at developing a universal ontology. Instead, individual metadata communities should concentrate on classifying and expressing semantics tailored toward distinct functional and community needs. Warwick Framework-like modularity underlies the design of the W3C's Resource Description Framework (RDF) [25], which is a modeling framework for the integration of diverse application and community-specific metadata vocabularies.
While the Warwick Framework proposes modularity as fundamental to a workable metadata strategy, it recognizes a number of challenges in the implementation of such. An outstanding one is the interoperability of multiple metadata packages that may be associated with and across resources. These packages are by nature not semantically distinct, but overlap and relate to each other in numerous ways. Achieving interoperability between these packages via one-to-one crosswalks [26] is useful, but this approach does not scale to the many metadata vocabularies that will inevitably develop.
A more scalable solution is to exploit the fact that many entities and relationships - for example, people, places, creations, organizations, events, certain relationships and the like - are so frequently encountered that they do not fall clearly into the domain of any particular metadata vocabulary but apply across all of them.
We are currently investigating a logical model for metadata interoperability [27] -- with the rather insipid title ABC -- that is examining the nature of these common entities and relationships. ABC is an attempt to:
The concepts and inter-relationships modeled in ABC could be used in a number of ways. In particular:
This research is in its early stages but will be the subject of a workshop held at the end of January 2000. This workshop will bring together a small number of experts from the metadata and data modeling community and will produce a document that refines a conceptual model that could be used and refined by individual metadata initiatives and application developers.
These are tumultuous times for scholarly publishing On the one hand, there is a sense of serious economic imbalance as subscription prices for scholarly journals rise at a rate far exceeding inflation and put tremendous pressure on flat research library budgets [28]. On the other hand, the rapid pace of advances in a number of disciplines (e.g, computer science, physics, law) conflicts with the relatively slow turn-around of the traditional scholarly publishing model.
A number of exciting initiatives are responding to these pressures. Several scholarly disciplines, especially the hard sciences, have launched ambitious e-print efforts. The most notable example is the physics archive (arxiv) hosted by Los Alamos National Laboratory. We at Cornell have been active in e-print initiatives within the computer science community both with NCSTRL (see Section 2.1) and CoRR (the Computer Resource Repository) [8]. In addition, a number of scholarly publications have been started that are only available in digital form. For example, Cornell and CNRI jointly publish D-Lib Magazine, a monthly publication documenting digital library research. Finally, many members of the traditional publishing community now make their publications available in electronic form (for example, the ACM digital library).
A prevailing meta-question in these digital publishing efforts is what is the proper model for interoperability amongst them? Researchers, who often cross disciplinary boundaries, will suffer a loss if the traditional single point of access offered by the print library catalog transitions in the digital age to a plethora of individual entry points.
These questions of interoperability are fundamentally those that we are examining in the context of our infrastructure research, described in Section 2.1. As part of this research, we are involved in the OAI (Open Archives Initiative) [29]. OAI developed at a meeting held in October 1999 in Santa Fe that was attended by a number of people already running digital scholarly archives or actively interested in the issue. The purpose of the meeting was to develop standards for interoperation. The meeting ended with agreement on a harvesting model of interoperability, whereby participating sites will follow a standard for making common and specific metadata available. This metadata can then be used by mediator services that build additional layers of functionality using this information. Some examples of these additional layers are federated searching, abstracting and indexing services, and so-called " overlay journals " (which combine documents from multiple resources into a virtual journal). One area of special interest in our research is reference linking, described in greater depth in Section 3.3.
The OAI agreement contains the following components:
The OAI is still in very early stages but it has already attracted a significant amount of attention from the scholarly community. From the standpoint of the research of the CDLRG it provides a number of benefits:
In general, digital library technology assumes that the user has a networked personal computer that is used to access server computers, which store content and provide information services. In practice, people increasingly use a variety of computing devices in their daily lives not all of which are continuously connected to a network. This growing proliferation of palm devices, hand-held computers, disconnected laptops, and embedded processors (e.g. " smart " mobile telephones) offer exciting opportunities for the creation of personalized information spaces -- digital libraries with collections and services that correspond to targeted needs and situations. Increasingly, we expect that individuals will want to exploit the mobility of these devices and use them for storage, access, and update of selected information resources when network access is impractical or impossible.
Developing and deploying these nomadic digital libraries will require technology that is sensitive to two critical dimensions of these devices:
These two dimensions can be characterized as device appropriateness. The CDLRG is currently undertaking a research and implementation project to investigate a number of the salient problems in realizing nomadic digital libraries that are sensitive to device awareness. This research program has the following components:
This section briefly summarizes the funded research projects of the Cornell Digital Library Research Group within which research on the above topics is being carried out.
Project Prism is project funded as part of the U.S. multiagency Digital Library Initiatives Phase 2. Prism is a collaboration between the CDLRG, the Cornell University Library, and the Cornell Human Computer Interface Group. The project is investigating integrity issues and policy enforcement in distributed digital libraries.
A particular focus of Prism is digital library preservation. The media has alerted the American public to the loss of valuable materials maintained only in electronic form [31]. As described in [32], there are no currently agreed-upon processes or model programs for preserving digital collections over time. Most existing digital preservation projects approach the problem from the narrow perspective of specific media or issues related to content alone. The Prism project is taking a broader approach that is examining preservation issues from both the policy and technical perspective.
Policy work on preservation within Prism involves librarians, archivists, and information specialists working together to develop formal functional requirements for digital preservation. This requirements definition work is focusing on factors related to digital object vulnerability and issues pertaining to preserving digital objects and associated services in a distributed environment, with the attendant "control zone" issues described in Section 2.3.
Technical work within Prism on preservation is focusing on the design and implementation of a Preservation Service as part of a wider component-based architecture. This service interacts with other digital library services to detect vulnerable objects and initiate preservation actions based on individual preservation policies. Among the tasks that such a service might perform are: broadcasting a preservation alert or a set of conditions that require preservation action, detecting objects that satisfy the conditions of the alert or a set of conditions that require preservation action, detecting objects that satisfy the conditions of the alert, disseminating object state information, or initiating a range of possible actions for preserving vulnerable objects. One challenge, as outlined in Section 2.3 is how to implement preservation tasks in the context of distributed content and services with varying levels of cooperation from the content and service providers.
Harmony is a funded as part of the Joint NSF-JISC International Digital Libraries Project. The project is an international collaboration involving the CDLRG and researchers from the United Kingdom and Australia.
Harmony is investigating the issue of metadata interoperability. Description of single-medium atomic digital resources has advanced in the past several years due to the development of metadata standards such as Dublin Core, which provides a framework for describing simple textual or image resources, and MPEG-7 [33], which will provide the same for audio, video, and audiovisual resources.
While such single medium documents are certainly useful and prevalent, the potential of digital libraries lies in their ability to store and deliver complex multimedia resources that combine text, image, audio and video components. The relationships between these components are multifaceted including temporal, spatial, structural and semantic and any descriptions of a multimedia resource must account for these relationships.
The Harmony Project is investigating a number of key issues in describing such complex multimedia resources in digital libraries with the following key goals:
The ABC workshop, described in Section 2.4, is being organized as part of the Harmony project.
OpCit, The Open Citation Project, is a three-year project (1999-2002) funded as part of the Joint NSF-JISC International Digital Libraries Project. The project is an international collaboration involving the CDLRG with researchers from the United Kingdom.
OpCit is investigating the issues of reference linking [30], a generalization of citation linking, which is well developed in the traditional information professions, and a refinement of hyper-linking, used on the Web. The goal of reference linking is to enable access to content -- which may be a digital object, a collection of digital objects, or a portion of a digital object -- from a reference to that content. The reference may be a URN, a URL, a formal citation in the form of a formatted bitliography entry, or an informal phrase that referes to a work -- for example, " Bill Arms' latest book on digital libraries ".
The OpCit project is following two inter-related paths:
The D-Lib Test Suite is a group of digital library testbeds, funded by DARPA, that are made available over the Internet for research in digital libraries, information management, collaboration, visualization, and related disciplines. The Test Suite currently includes six testbeds, one of which is the NCSTRL collection developed and administered by the CDLRG.
NCSTRL (pronounced "ancestral") is an international collection of computer science research reports and other materials made available for non-commercial use from over 100 participating organizations worldwide. By and large these organizations are Ph.D. granting computer science departments, e-print repositories, electronic journals, and research laboratories. The NCSTRL collection is continually growing as new institutions become participants and as existing institutions add new documents. Documents in the NCSTRL collections are almost all textual ranging in size from 100-plus page doctoral dissertations to short technical reports.
NCSTRL is a federated digital library; content, and services that provide access to the content, are distributed over sites in North America, Europe and Asia. Interaction between services and access to documents is via the Dienst protocol (described in Section 2.1), an open service-based protocol for distributed digital libraries.
The Nomadic Digital Libraries Project, recently begun, is a small Intel-funded project to investigate the application of distributed digital library technology to nomadic (disconnected or randomly connected) devices (e.g. palm devices, hand-helds, and roaming laptops). This project is one component of a developing nomadic computing research focus in the Cornell Computer Science department.
This paper has described research of the Cornell Digital Library Research Group in a number of areas that are important to this future progress. Work on architectural components lays the groundwork for moving digital libraries from local to diverse and broadly distributed systems. Work on digital object architectures provides the mechanisms for rich and varied content in digital libraries. Work on policy enforcement investigates the key issue of extending information integrity, which is so well established and important in " brick and mortar " libraries, to the distributed digital domain. Work on new publishing models examines information distribution techniques that exploit these new architectures. Finally, work on nomadic devices investigates extending these techniques to the latest developments in hardware and networking.
We look forward to these projects contributing valuable results and generating intellectual energy for future research efforts.
[1] C. Lagoze and S. Payette, "An Infrastructure for Open Architecture Digital Libraries, " Cornell University Computer Science, Technical Report TR98-1690, June 1998.
[2] B. M. Leiner, " The NCSTRL Approach to Open Architecture for the Confederated Digital Library, " in D-Lib Magazine, 1998.
[3] J. R. Davis, D. B. Krafft, and C. Lagoze, " Dienst: Building a Production Technical Report Server, " in Advances in Digital Libraries: Springer-Verlag, 1995, pp. Chapter 15.
[4] J. R. Davis and C. Lagoze, " A protocol and server for a distributed digital technical report library, " Cornell University Computer Science, Technical Report TR94-1418, June 1994.
[5] C. Lagoze, E. Shaw, J. R. Davis, and D. B. Krafft, " Dienst Implementation Reference Manual, " Cornell University Computer Science, Technical Report TR95-1514, May 1995.
[6] J. R. Davis and C. Lagoze, " The Networked Computer Science Technical Report Library, " Cornell University Computer Science, Technical Report TR96-1595, July 1996.
[7] J. R. Davis and C. Lagoze, " NCSTRL: Design and Deployment of a Globally Distributed Digital Library, " to appear in Journal of the American Society for Information Science (JASIS), 2000.
[8] J. Y. Halpern and C. Lagoze, " The Computing Research Repository: Promoting the Rapid Dissemination and Archiving of Computer Science Research, " presented at Digital Libraries '99, The Fourth ACM Conference on Digital Libraries, Berkeley, CA, 1999.
[9] A. Andreoni, M. B. Balducci, S. Biagioni, C. Carlesi, D. Castelli, P. Pagano, C. Peters, and S. Pisani, " The ERCIM Technical Reference Library, " D-Lib Magazine, vol. 5, 1999.
[10] N. Dushay, J. C. French, and C. Lagoze, " A Characterization Study of NCSTRL Distributed Searching, " Cornell University Computer Science, Technical Report TR99-1725, January 1999.
[11] N. Dushay and J. C. French, " Using Query Mediators for Distributed Searching in Federated Digital Libraries, " presented at Digital Libraries '99: The Fourth ACM Conference on Digital Libraries, Berkeley, 1999.
[12] N. Dushay, J. C. French, and C. Lagoze, " Predicting Performance of Indexers in a Distributed Digital Library, " Cornell University Computer Science, Ithaca, NY, Technical Report TR99-1743, May 1999.
[13] C. Lagoze, D. Fielding, and S. Payette, " Making Global Digital Libraries Work: Collection Service, Connectivity Regions, and Collection Views, " presented at ACM Digital Libraries '98, Pittsburgh, 1998.
[14] C. Lagoze and D. Fielding, " Defining Collections in Distributed Digital Libraries, " D-Lib Magazine, 1998.
[15] R. Kahn and R. Wilensky, " A Framework for Distributed Digital Object Services, " Coporation for National Research Initiatives, Reston, Working Paper cnri.dlib/tn95-01, 1995.
[16] C. Lagoze and D. Ely, " Implementation Issues in an Open Architectural Framework for Digital Object Services, " Cornell University, Computer Science Technical Report TR95-1540, September 1995.
[17] S. Payette and C. Lagoze, " Flexible and Extensible Digital Object and Repository Architecture (FEDORA), " presented at Second European Conference on Research and Advanced Technology for Digital Libraries, Heraklion, Crete, 1998.
[18] S. Payette, C. Blanchi, C. Lagoze, and E. Overly, " Interoperability for Digital Objects and Repositories: The Cornell/CNRI Experiments, " D-Lib Magazine, vol. May, 1999.
[19] R. Atkinson, " Library Functions, Scholarly Communication, and the Foundation of the Digital Library: Laying Claim to the Control Zone, " The Library Quarterly, 1996.
[20] F. B. Schneider, " Enforceable Security Policies, " Cornell University, Department of Computer Science, Computer Science Technical Report TR98-1664, 1998.
[21] M. Stefik, " The Digital Property Rights Language: Manual and Tutorial, " Xerox Palo Alto Research Center, Palo Alta, CA, Limited Distribution Document September 1996.
[22] C. Lagoze, C. A. Lynch, and R. D. Jr., " The Warwick Framework: A Container Architecture for Aggregating Sets of Metadata, " Cornell University Computer Science, Technical Report TR96-1593, June 1996.
[23] C. Lagoze, The Warwick Framework: A Container Architecture for Diverse Sets of Metadata, " in D-Lib Magazine, 1996.
[24] R. Daniel Jr. and C. Lagoze, " Distributed Active Relationships in the Warwick Framework, " presented at IEEE Metadata Conference, Bethesda, 1997.
[25] O. Lassila and R. R. Swick, " Resource Description Framework: (RDF) Model and Syntax Specification, " World Wide Web Consortium, W3C Proposed Recommendation PR-rdf-syntax-19990105, January 1999.
[26] " Dublin Core/MARC/GILS Crosswalk, " : Library of Congress, Network Development and MARC Standards Office, 1997.
[27] D. Brickley, J. Hunter, and C. Lagoze, " ABC: A Logical Model for Metadata Interoperability, " , Harmony discussion note 1999.
[28] B. L. Hawkins, " The Unsustainability of the Traditional Library and the Threat to Higher Education, " in The mirage of continuity: reconfiguring academic information resources for the 21st century, B. L. Hawkins and P. Battin, Eds. Washington, DC: Council on Library and Information Resources, 1998.
[29] H. v. d. Sompel and C. Lagoze, " The Open Archives Initiative, " D-Lib Magazine, vol. 6, 2000.
[30] W. Y. Arms and P. Caplan, " Reference Linking for Journal Articles, " D-Lib Magazine, 1999.
[31] S. Manes, " Time and Technology Threaten Digital Archives, " in New York Times. New York, 1998.
[32] Joint Research Libraries Group/Commission on Preservation and Access Task Force on Archiving of Digital Information, " Preserving Digital Information: Final Report and Recommendations, " , Washington, DC 1997.
[33] " MPEG-7 Requirements Document, " International Organisation for Standardisation, Requirements IDO/IEC JTC1/SC29/WG11, October 1998.